





31. 03. 2025
NetEye, Service Management

06. 11. 2024
Davide Sbetti
AI, Log-SIEM, Machine Learning, NetEye
The New NetEye User Guide Search: From POC to Production
Hello everyone!
As you may remember, a topic I like to discuss a lot on this blog is the Proof of Concept (POC) about how we could enhance search within our online NetEye User Guide.
Well, we’re happy to share with you how we’ve further developed the POC, specifically the process outlined in the first two parts (you can still see the first and second parts if you’re interested) and we brought it into production 🎉
Sooo… how does searching the NetEye User Guide work now?
Cutting Pages into Pieces (a.k.a. During the User Guide builds)
Okay, so whenever we’d like to release some new content into the User Guide, a specific pipeline is executed in our Open Shift environment. Now, an additional step is performed during that pipeline, to build the foundations of our new search.
More specifically, we create an Elasticsearch document for each section of each HTML page in the User Guide, to make it searchable using a semantic search approach, through the ELSER model, also developed by Elastic.
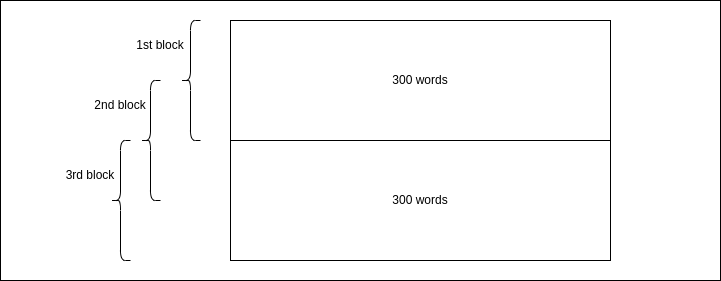
Actually, since ELSER has a constraint on the number of input tokens, we create at least one document for each section, using a sliding window approach where each window has a size of about 300 words and slides in steps of half that size.
What does this mean? Basically, we take the first 300 words of a section, make a document out of them and, if the section is longer, we move forward by 150 words and create a second document. This process is then repeated until we reach the end of the section.
And yes, it is true that Elasticsearch recently added the semantic text data type, which performs a very similar operation automatically, but while we were developing our solution it wasn’t available yet 😉
After this process has been completed, we send the documents to an Elasticsearch instance where we apply the ELSER model through an ingest pipeline and the inference processor, in a way that’s really similar way to the one we adopted during the POC.
This allows us to obtain documents containing a vector representation of the concepts found in the section text, and not just related to the actual words used to express them, allowing us to then match the documents and the user’s query not only based on the words they share but the actual concepts.
What is the difference compared to the POC? Well, actually that all of this wasn’t performed using a Python script as we did in the POC, but now runs in a container and was developed in… Rust 🦀, the language we’re adopting most of the time for our backend services.
The second important point that we’d like to highlight is that during the pipeline, we compare the HTML files we just built with the ones currently in production, and we process only those documents that have changed, to avoid performing unnecessary work.
Furthermore, the entire indexing process is performed on an index cloned from the production index, and that’s linked to the build that we’re currently running.
Let’s Switch Aliases (a.k.a When We Release the User Guide)
Okay, so that was during the build of the User Guide, but what happens when we actually release the new User Guide content that we were building?
Well, at that point, we switch the Elasticsearch alias neteye-guide in our Elasticsearch instance to point to the index corresponding to the version of the User Guide that we’re now releasing, i.e. the one related to the build that we just performed. This allows us to separate the build process from the release process, and also to perform rollbacks not only of the HTML content but also of the searchable content, in case that’s needed.
Why an alias? You’ll find out in just one… paragraph!
When the user searches (a.k.a day to day usage)
Whenever the user searches for something in the new search bar, the search request reaches our brand new search server, developed, you guessed it! in Rust 🦀
Our search server forwards the search request to our Elasticsearch instance, applying a semantic query targeting the index pointed to by the neteye-guide alias, to retrieve the 10 most relevant results from the index currently used in production. In this context, the alias is quite useful to avoid having to adapt the search server every time we release some new content.
Since the whole section text is returned for each result by Elasticsearch, our search server creates a context sentence for each result, by taking the 30-word sub-sequence that contains the largest number of occurrences of the user’s query words.
After processing the query results, they’re returned back to our users.
Conclusion
In this blog post I showed you how we improved and refined the POC that we started as part of an innovative project, and how we actually brought it into production.
Of course, feel free to try it out and let us know what you think about it 😄
See you at the next blog post 👋
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.
Davide Sbetti
Hi! I'm Davide and I'm a Software Developer with the R&D Team in the "IT System & Service Management Solutions" group here at Würth Phoenix. IT has been a passion for me ever since I was a child, and so the direction of my studies was...never in any doubt! Lately, my interests have focused in particular on data science techniques and the training of machine learning models.
Author
Latest posts by Davide Sbetti
31. 03. 2025
Development, DevOps, NetEye
Reducing the NetEye ISO Size: How to Carefully Choose the Right Packages!