





20. 12. 2024
Atlassian, NetEye, Service Management

12. 08. 2024
Davide Sbetti
AI, Artificial Intelligence, Log-SIEM, Machine Learning, NetEye
Bring Your Own Model – Using Custom Models in Elasticsearch
Hey everyone!
As you may remember, we took a look in the past at how it’s possible to use a model (trained directly in Elasticsearch) to perform some real time classification by using an ingest pipeline.
But… what if we wanted to use our own externally trained model?
Well the good news is that, under certain limits, we can!
That’s because Elasticsearch supports importing certain external models, using the Eland tool. How does this work? Well, let’s dive in together!
Note: if you’re interested in the actual code and data discussed in this blog post, please go ahead and check them out in the attached archive, which also contains a Jupyter notebook that can be easily run to replicate all the described steps.
Training a model
To be able to import a model into Elasticsearch, we need… a model!
Continuing with what we already explored in that previous blog post, we can try to train a super-simple model that’s able to classify the collected radar signals into “good” and “bad” for the target research, where “good” signals are those that provide enough information for the research, starting from the data set of already-collected signals.
Please note that our focus is not on training the best possible model, but to show the entire process including how to load and test it in Elasticsearch. So we won’t concentrate too much on additional steps (such as Standardization) that may be more suitable for models that will be in production.
This time we’ll perform the training step outside the Elastic Stack environment, using scikit-learn.
Inspecting the data
First of all, let’s import the necessary libraries.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
Then we can import the radar signals from the CSV file that our scientists kindly provided. Let’s take a look at the first few rows.
radar_data = pd.read_csv('ionosphere.csv')
radar_data.head()
| attribute1 | attribute2 | attribute3 | ….. | attribute34 | class |
| 0.99539 | -0.05889 | 0.85243 | … | -0.45300 | good |
| 1 | -0.18829 | 0.93035 | … | -0.02447 | bad |
| 1 | -0.03365 | 1 | … | -0.38238 | good |
| 1 | -0.45161 | 1 | … | 1 | bad |
As we can see, we have 34 numerical attributes and the final classification.
Our next step is to divide the attributes from the classification and transform this to a number, to make it more digestible to our model.
# Separate the attributes from the class column
x, y_raw = (radar_data.iloc[:, :-1].values,
radar_data.iloc[:, -1].values)
# Map the classes to actual numbers
y = np.array([1 if label == 'good' else 0 for label in y_raw])
Let’s train a bit
We can then divide our data set into two parts, one used during training and one kept aside to see how the model performs after the training phase has finished (testing). Luckily, scikit-learn helps us with this, allowing us to specify the percentage of the data we would like to keep for training (in this case 70%) and also making it easier to shuffle them around a bit.
X_train, X_test, y_train, y_test = train_test_split(
x,
y,
train_size=0.7,
shuffle=True
)
And next it’s time to train our classifier! Unfortunately not all models are supported by Eland, but by looking at the list of available options, we can decide to train, for example, a classifier based on Decision Trees.
classifier = DecisionTreeClassifier()
classifier = classifier.fit(X_train, y_train)
Once we’ve trained the model, we can evaluate its accuracy on the test set we previously split out and set aside. Note that with so few data points something like cross-fold validation may have been more appropriate, but that’s outside the scope of this article.
y_pred = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
In my case this returned an accuracy of about 89%.
Optionally, we can save our model for later use, using for example the ONNX format.
Loading our model into Elasticsearch
Okay, now that we have an actual model compatible with Eland, we can load it into our target Elasticsearch instance.
Let’s import the additional libraries we’ll need for this:
from eland.ml import MLModel
from elasticsearch import Elasticsearch
First, we need to create an Elasticsearch client instance, using the desired authentication method (username/password or certificate-based authentication).
es = Elasticsearch(
hosts=["https://localhost:9200"],
basic_auth=("<user>", "<password>")
)
And then it’s time to import the model into Elasticsearch, an operation that we can perform in… one line!
es_model = MLModel.import_model(
es_client=es,
model_id="radar-classifier-v1",
model=classifier,
feature_names=radar_data.columns[:-1].tolist(),
)
The result? By consulting the page of Trained Models under the Machine Learning section in Kibana, we can see that our model was successfully imported!
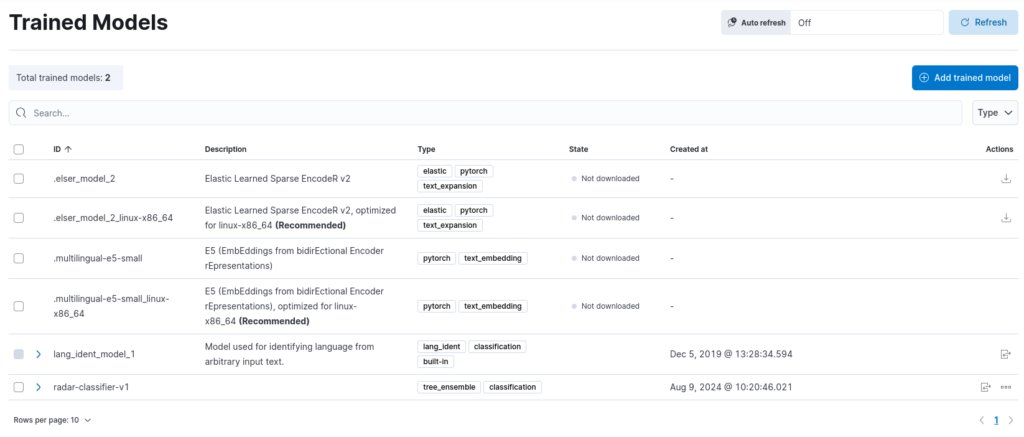
Testing the imported model
And now that we’ve loaded the model in Elasticsearch, we can test it to ensure that everything works fine, just as we did when we trained it directly in Elasticsearch.
We can use the overflow menu on the right hand side of our model to choose the Test model action. We can also re-use our document from last time to test the new model, pasting the following content into the Raw document text box.
[
{
"_source": {
"attribute1": 1,
"attribute2": 0,
"attribute3": 0.84710,
"attribute4": 0.13533,
"attribute5": 0.73638,
"attribute6": -0.06151,
"attribute7": 0.87873,
"attribute8": 0.08260,
"attribute9": 0.88928,
"attribute10": -0.09139,
"attribute11": 0.78735,
"attribute12": 0.06678,
"attribute13": 0.80668,
"attribute14": -0.00351,
"attribute15": 0.79262,
"attribute16": -0.01054,
"attribute17": 0.85764,
"attribute18": -0.04569,
"attribute19": 0.87170,
"attribute20": -0.03515,
"attribute21": 0.81722,
"attribute22": -0.09490,
"attribute23": 0.71002,
"attribute24": 0.04394,
"attribute25": 0.86467,
"attribute26": -0.15114,
"attribute27": 0.81147,
"attribute28": -0.04822,
"attribute29": 0.78207,
"attribute30": -0.00703,
"attribute31": 0.75747,
"attribute32": -0.06678,
"attribute33": 0.85764,
"attribute34": -0.06151
}
}
]
Then by simulating the pipeline we can see how the document is assigned the class 1, namely a good radar signal, the same conclusion we drew when applying the model trained in Elasticsearch!
We can now apply the model using an ingest pipeline and the inference processor to our incoming documents in real time!
Conclusions
In this article we saw how it’s possible to train a simple model and load it in Elasticsearch, something that can allow us to apply an externally trained model to the documents we ingest.
References
Ionosphere Data Set: Blake, C., Keogh,E and Merz, C.J. (1998). UCI Repository of machine learning databases [https://archive.ics.uci.edu/ml/index.php]. Irvine, CA: University of California, Department of Information and Computer Science
Attachments
These Solutions are Engineered by Humans
Are you passionate about performance metrics or other modern IT challenges? Do you have the experience to drive solutions like the one above? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles just like this as well as other roles here at Würth Phoenix.
Davide Sbetti
Hi! I'm Davide and I'm a Software Developer with the R&D Team in the "IT System & Service Management Solutions" group here at Würth Phoenix. IT has been a passion for me ever since I was a child, and so the direction of my studies was...never in any doubt! Lately, my interests have focused in particular on data science techniques and the training of machine learning models.
Author
Latest posts by Davide Sbetti
20. 12. 2024
Automation, Development, NetEye
When Less is More: NetEye Update and Upgrade Checkpoints
06. 11. 2024
AI, Log-SIEM, Machine Learning, NetEye
The New NetEye User Guide Search: From POC to Production