







31. 03. 2025
NetEye, Service Management

02. 08. 2017
Susanne Greiner
NetEye, Real User Experience Monitoring
Next Level Performance Monitoring: il ruolo di machine learning e anomaly detection [Seconda parte]
Machine learning e anomaly detection sono procedimenti utilizzati sempre con più frequenza nell’area del performance monitoring. Ma di cosa si occupano realmente e perché l’interesse in quest’area sta aumentando così rapidamente?
Dalla statistica al machine learning
Sono stati fatti diversi tentativi per definire le principali differenze tra machine learning e statistica, ma non è sempre così netta la distinzione, infatti ci sono pareri contrastanti anche tra gli esperti:
- “Non ci sono differenze tra machine learning e statistica” (in termini di matematica, libri, metodi di apprendimento, ecc.)
- “Il Machine Learning è completamente diverso dalla statistica.” (e solo il primo resisterà in futuro)
- “La statistica è l’unico vero e il solo approccio” (Il Machine Learning è un termine diverso per definire una parte della statistica da parte di persone che non capiscono il reale concetto matematico)
I lettori interessati possono fare riferimento a:
Breiman – Statistical Modeling: The Two Cultures e Statistics vs. Machine Learning, fight!
Non riusciremo ad argomentare brevemente in questo post la risposta al quesito, ma possiamo affermare che, nell’ambito del monitoraggio informatico, il machine learning e la statistica si focalizzano al momento su diversi fronti ed è quindi essenziale utilizzarli entrambi. La statistica si occupa dello studio delle inferenze (ha come obbiettivo di inferire le proprietà del processo che ha generato i dati) mentre il machine learning si focalizza sulla predizione (cerca di predire come saranno i dati nel futuro). Ovviamente i due procedimenti non sono del tutto indipendenti. L’impiego di entrambi gli approcci può creare algoritmi sempre migliori di previsione o di anomaly detection.
Anomaly Detection e allarmistica standard
Una volta l’utilizzo delle baseline sembrava LA soluzione per la definizione di allarmi significativi. Oggi, dato che il traffico di rete è sempre più eterogeneo, anche a causa dell’avvento dell’Internet of Things, è necessario valutare nuove strategie. Ed è proprio qui che entra in gioco l’anomaly detection. Cos’è considerato effettivamente un’anomalia? È un valore che per qualche motivo non è da considerarsi standard. Questi valori vengono classificati in diverse tipologie:
- Anomalie a punto – Point anomalies:
Un singolo dato (data point) è diverso da tutto il resto. Ad esempio potrebbe succedere che un processore che oscilla sempre tra un certo range ad un certo punto presenta un picco al di fuori di questo range.
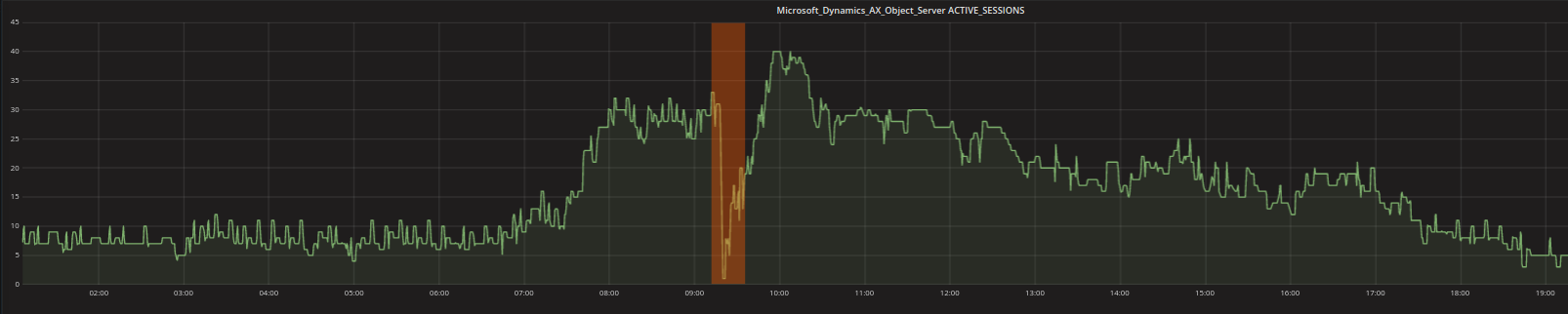
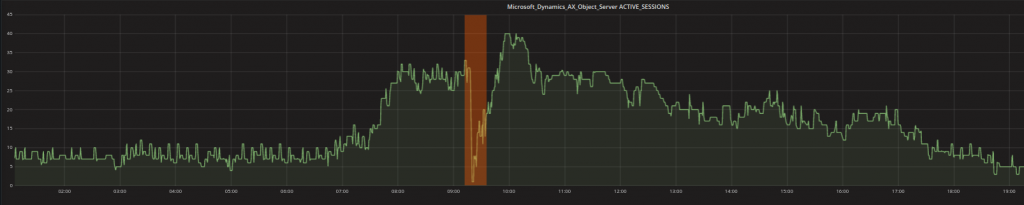
- Anomalie contestuali – contextual anomalies : Uno o più punti di dati possono essere rilevati come anomalie, quando risultano strani in uno specifico contesto. Per esempio valori che si riscontrano tipicamente di notte potrebbero non essere altrettanto comuni durante il giorno. I valori bassi mostrati nel grafico sotto (evidenziati di arancione) non sono strani perchè minimi (infatti ci sono molti altri valori simili nel grafico) MA devono essere rilevati perchè registrati durante la giornata lavorativa durante la quale ci si aspetta di avere valori maggiori.
- Anomalie collettive – collective anomalies: Diversi valori registrati contemporaneamente possono anche essere un segnale che esiste un’anomalia (più dati o metriche insieme, e non valori singoli). Le due tipologie più comuni sono eventi con una sequenza inaspettata e una combinazione inattesa di valori. Per esempio, un picco di un processore potrebbe essere perfettamente plausibile se esistono richieste di transazione sulle quali il processore sta lavorando. Un picco del processore con altre metriche che indicano che il sistema è inattivo indica invece che qualcosa è andato storto durante il processo investigativo.
Cosa significa? Con parole semplici, significa che ci sono alcune situazioni in cui i metodi standard non sono in grado di innescare un allarme perchè alcune casistiche possono essere rilevate solamente da tecniche più sofisticate rispetto all’utilizzo delle baseline. Non sto dicendo che queste tecniche più sofisticate sostituiscono completamente le baseline ma costituiscono una valida aggiunta alla metodologia standard, specialmente nel caso in cui si verificano conseguenze significative dovute al fatto che queste anomalie non sono state riscontrate.
Next Level Performance Monitoring
Analizziamo come un rilevamento di anomalie può arricchire il potenziale della soluzione di Performance Monitoring di nuova generazione di Würth Phoenix. Per esempio, quale processo seguirebbe un esperto durante la fase di analisi delle ragioni che hanno causato un rallentamento di sistema?
- Controlla che esiste realmente un problema
- Cerca di identificare da dove esso provenga
- Analizza la situazione
- Risolve il problema e considera eventuali azioni da intraprendere per evitare in futuro simili circostanze
In pratica questo processo potrebbe essere:
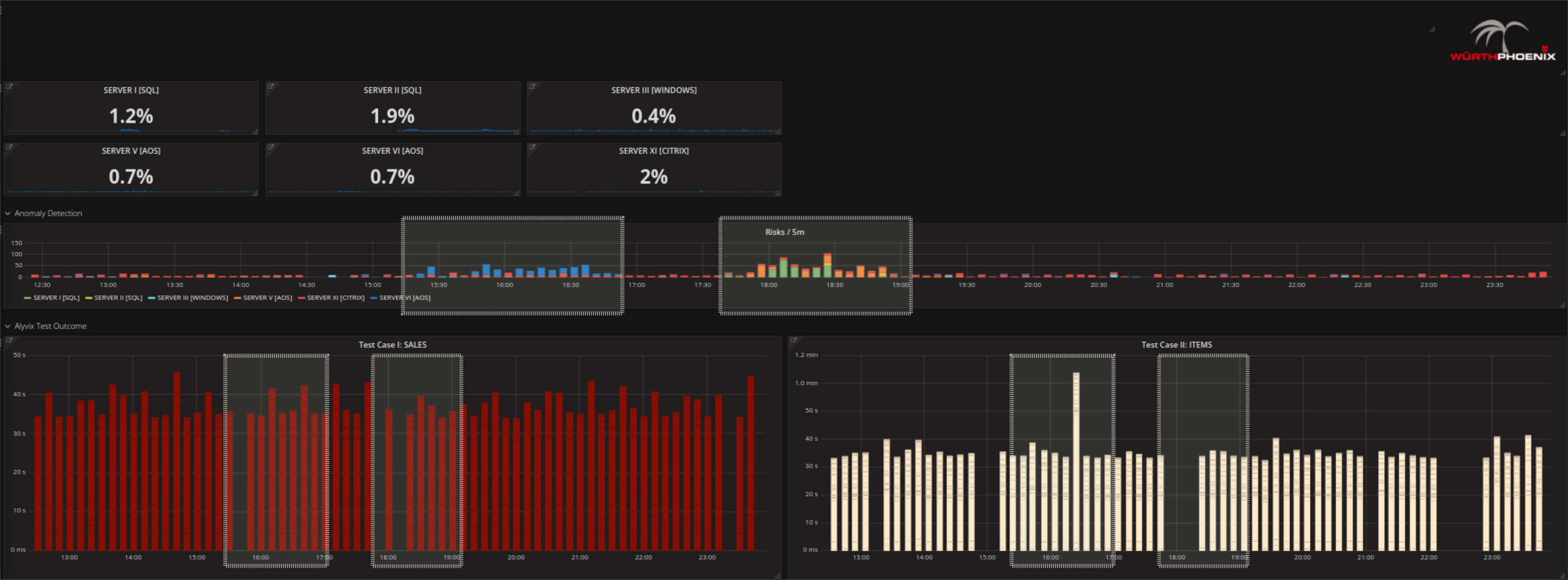
- Controlla con Alyvix e l’anomaly detection se esiste un problema reale. Constata che il problema esiste, dato che Alyvix mostra un test con ritardi significativi e un periodo in cui non sono registrati dati (spazi neri tra le barre). L’anomaly detection (grafico centrale nell’immagine) mostra punti temporali che possono essere considerati a rischio rispetto alle attività standard nello stesso periodo.
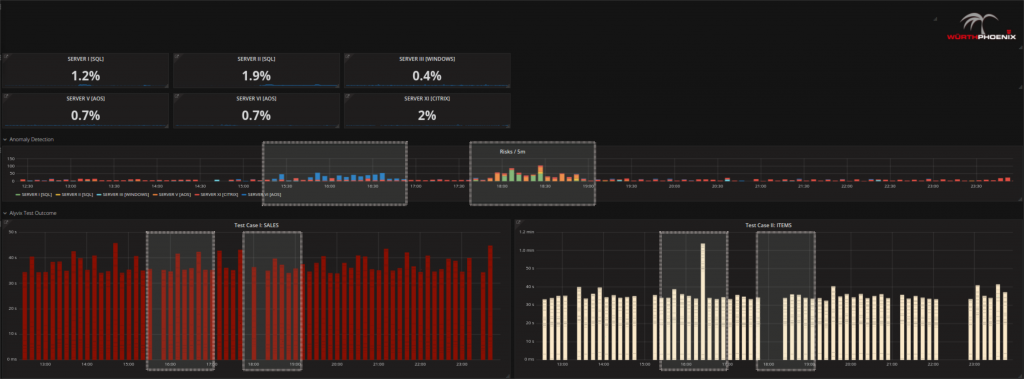
- Cerca di identificare da dove prevenga il problema:
Se si ha il sospetto che il problema sia stato causato da un server specifico, è sufficiente cliccare sulla panoramica del server per controllare i dettagli. Altrimenti, basterà muoversi con il mouse sui rischi rilevati dall’anomaly detection e procedere nel controllo sistematico dei dettagli fino a identificare l’origine del problema.
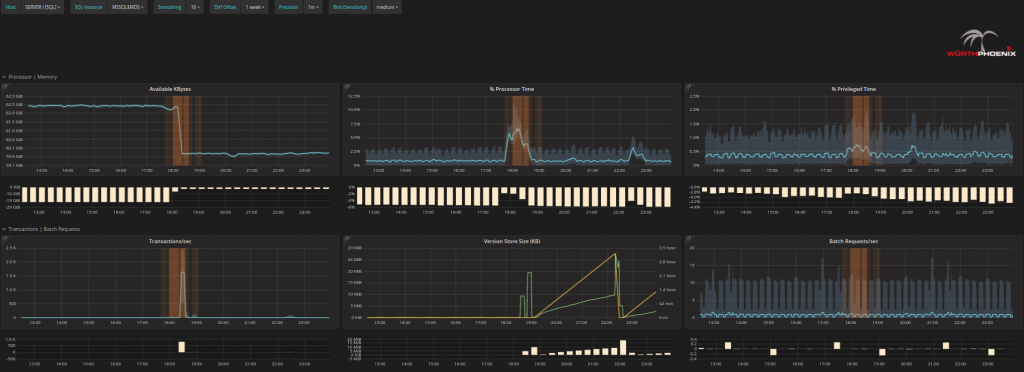
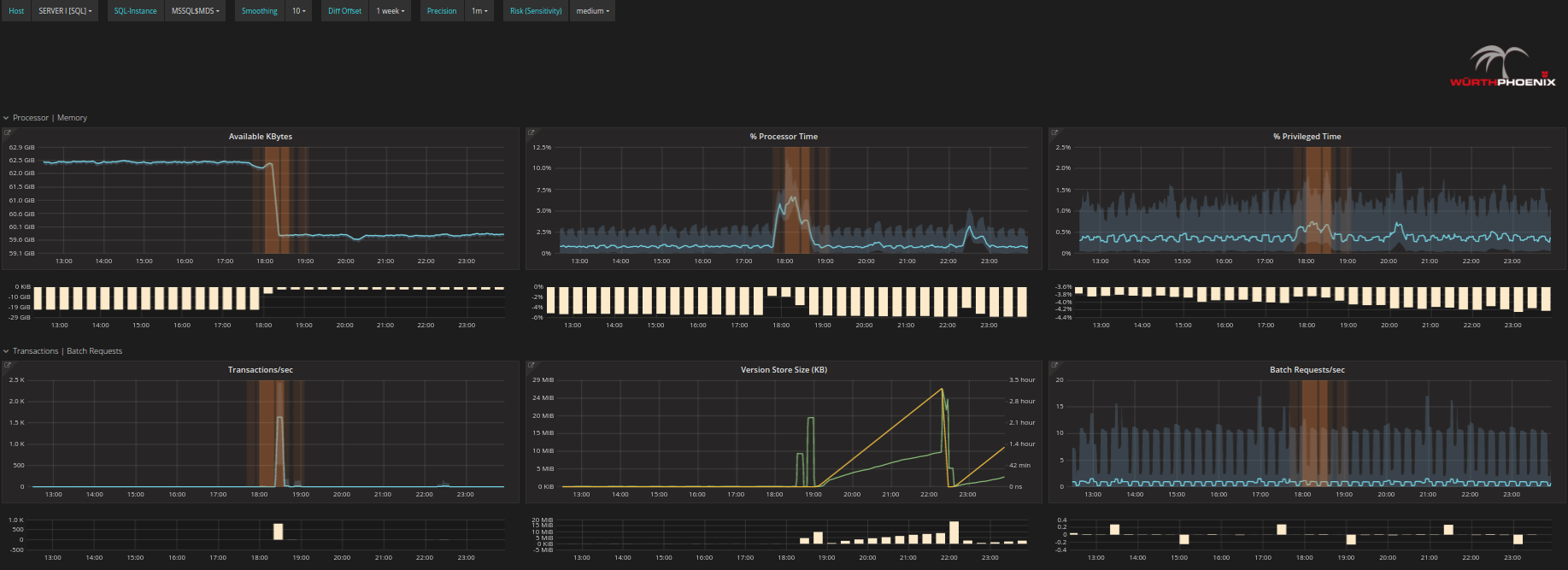
- Analizza la situazione:
È possibile analizzare ogni problema fino alla singola operazione sul singolo disco e sul singolo processore per controllare i cambiamenti nel loro comportamento e comprendere in dettaglio cosa è realmente accaduto o potrebbe succedere in futuro.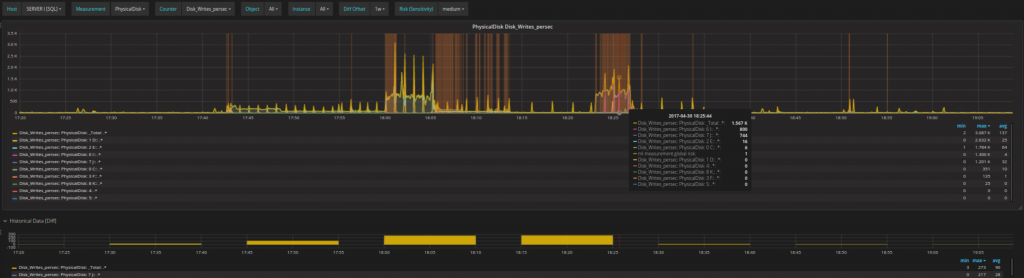
- Risolve il problema e considera eventuali azioni da intraprendere per evitare in futuro simili circostanze.
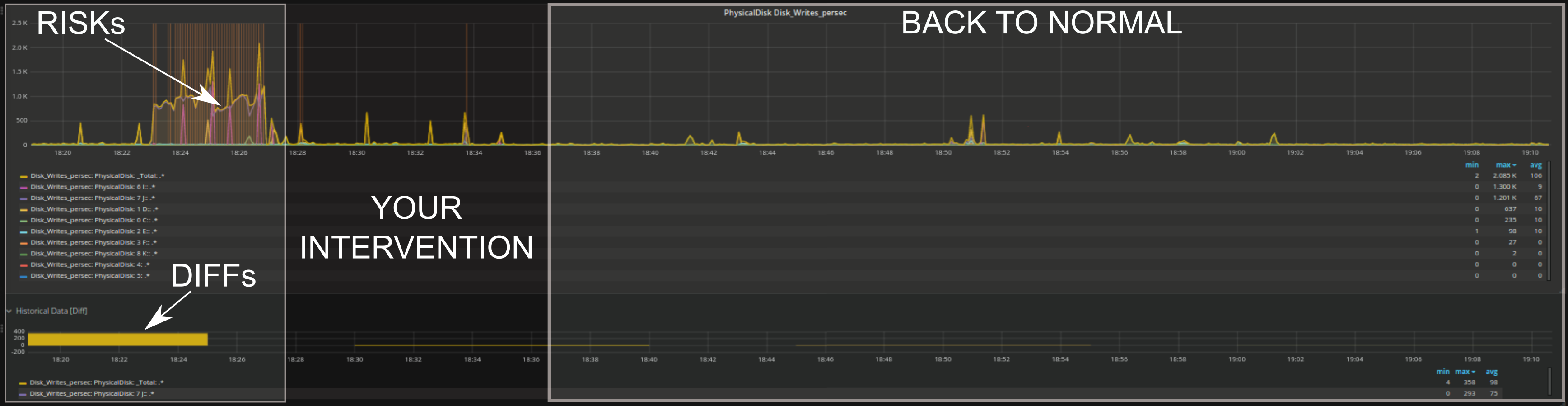
Si può avere un riscontro immediato se l’intervento ha corretto il problema o ha portato a degli effetti positivi come la diminuzione dei rischi, dei DIFF (differenze con i valori storici) o simili.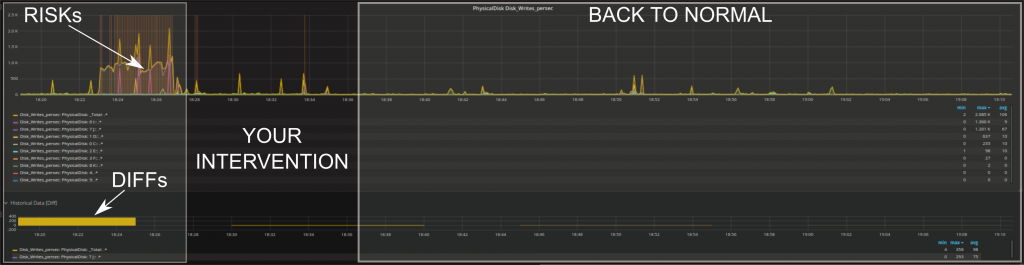
Come avete letto sopra, abbiamo implementato un procedimento di rilevamento delle anomalie (anomaly detection) nella forma di rischi (RISKs). Un rischio (RISK), in questo contesto, è considerato come ogni valore che si discosta dal comportamento abituale. Le metodologie tradizionali (come ad esempio la baseline) hanno un solo modo per determinare se un comportamento è inusuale; per esempio, possono identificare solo eventi al di fuori del range standard di ogni singola metrica. L’anomaly detection, invece, è in grado di identificare molteplici tipologie di cambiamenti ed è dinamica nel tempo.
Il vantaggio del performance monitoring di nuova generazione che utilizza l’anomaly detection risulta quindi evidente. I rischi possono velocizzare il processo di identificazione dei periodi temporali più critici. I periodi non ordinari dovrebbero essere considerati nella fase di troubleshotting, perchè la probabilità che siano collegati all’origine del problema è molto alta. Analisi variegate consentono di analizzare il comportamento di molte metriche insieme e di studiare le loro relazioni, mentre l’occhio umano non sarebbe in grado. Gli algoritmi di anomaly detection possono diventare con il tempo più accurati aggiungendo più informazioni alle metriche di performance, attingendo dinamicamente dai dati storici, o integrando le conclusioni raggiunte attraverso l’analisi degli esperti. In conclusione, si potrebbe dire che utilizziamo l’anomaly detection all’interno della nostra soluzione come primo indicatore per sapere da dove iniziare il processo di analisi. Ci si può aspettare che i risultati possano sovrapporsi con gli allarmi generati dal monitoraggio tradizionale, ma è anche possibile identificare preventivamente combinazioni diverse che potrebbero essere potenzialmente molto pericolose. Infine l’output dell’anomaly detection può essere combinato con gli allarmi standard per esempio per filtrarli in gruppi di eventi con più o meno relazionalità.

Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential