





31. 03. 2025
NetEye, Service Management

20. 06. 2017
Susanne Greiner
NetEye, Real User Experience Monitoring
Next Level Performance Monitoring – Part I
Oggigiorno il traffico di rete sta diventando sempre più eterogeneo. In tanti casi non è sufficiente monitorare un sistema con gli stessi metodi utilizzati in passato. Presenterò di seguito quelli che, secondo Würth Phoenix, sono i punti chiave per un monitoraggio all’avanguardia e un’analisi proattiva delle applicazioni critiche per il vostro business.
Combinazione User Experience a Metriche delle Performance per nuove conclusioni
Ritengo importante trattare per primo il tema della combinazione della User Experience e delle metriche in quanto considero la User Experience un fattore determinante nell’utilizzo di un sistema. Infatti se un utente lamenta cattive prestazioni del sistema, si ritiene necessario migliorarle anche nel caso in cui le metriche riportino buoni valori.
Si considera di importanza vitale sapere quando gli applicativi rallentano, se possibile prima che gli utenti lamentino un disservizio. Si può raggiungere questo obiettivo grazie all’aiuto di Alyvix, la nostra soluzione di user experience monitoring attivo, che permette di effettuare frequenti check. Con Alyvix è possibile scrivere dei test-case su misura, che controllano le parti più importanti, le funzionalità e le performance (in termini di durata) degli applicativi.
Il risultato dell’analisi delle performance di ogni singolo test viene salvato su un database centralizzato, lo stesso nel quale vengono memorizzate anche tutte le altre (per esempio dati perfmon, esxtop, e altri). Grazie al multiserver zoom è possibile visualizzare e analizzare nel dettaglio i dati registrati negli intervalli temporali in cui Alyvix ha registrato dei problemi.
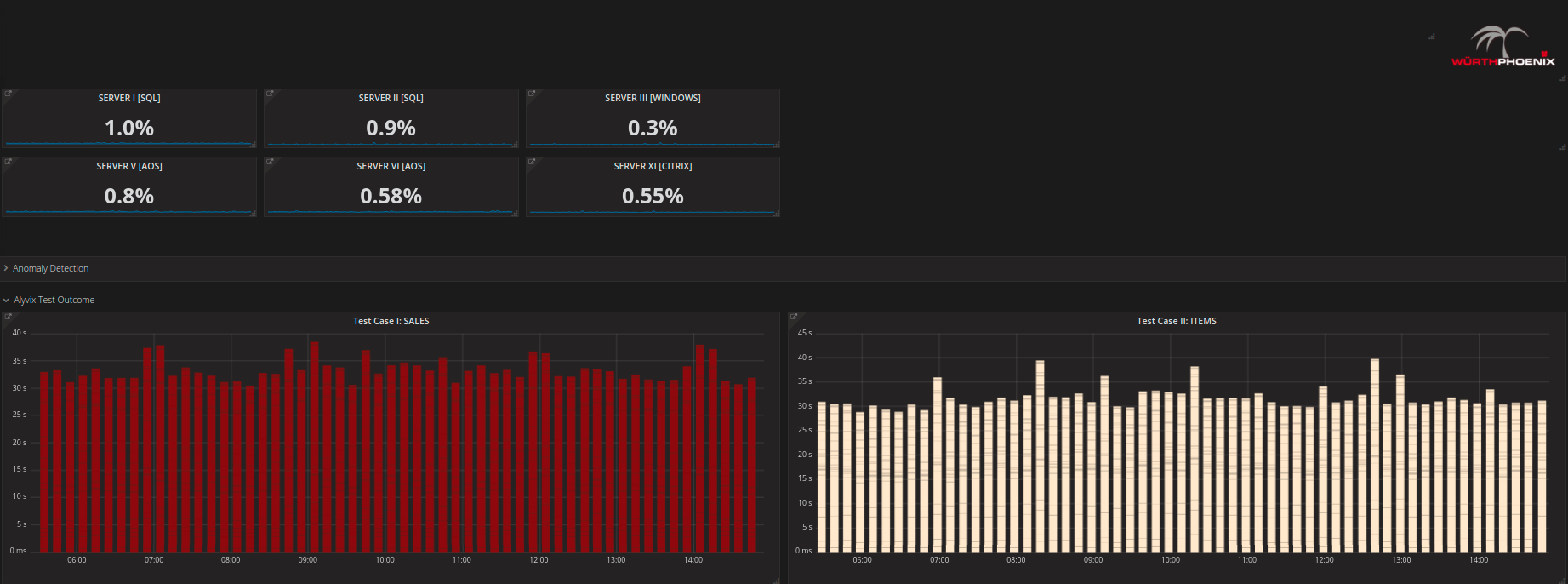
Grazie alla dashboard principale si può avere una visione più dettagliata dei test Alyvix, essa rende facilmente individuabili i picchi temporali, permettendo di capire se la loro maggiore durata è legata ad un singolo test o ad una serie di analisi. In altre parole permette di individuare quali parti dell’applicativo risultano critiche e stanno creando dei rallentamenti.
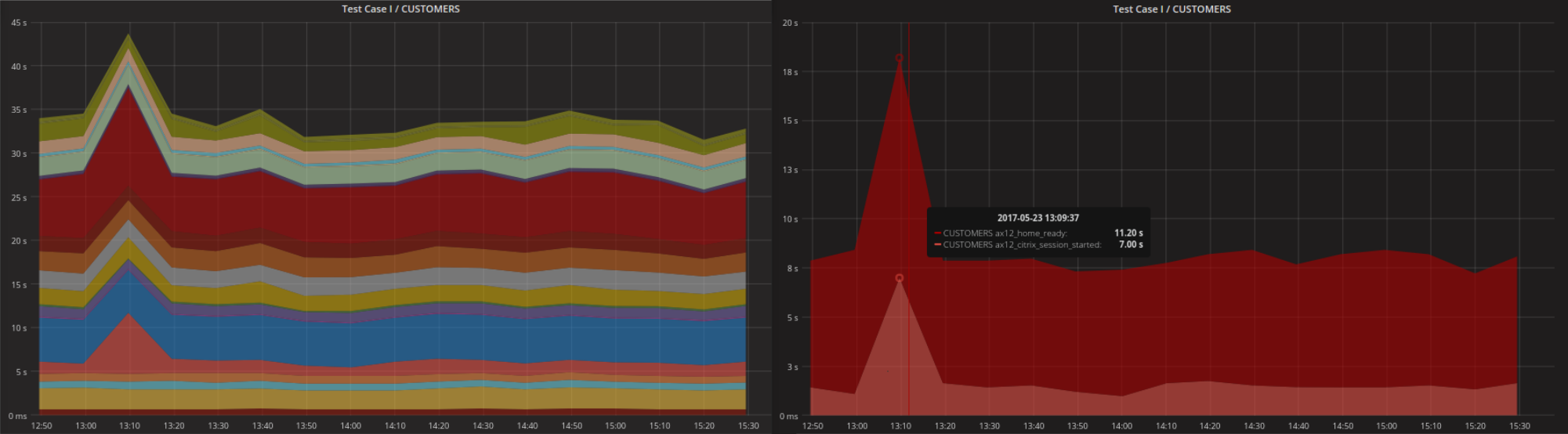
Partendo dalla dashboard principale è possibile raggiungere con un semplice click una dashboard più dettagliata, contenente i dati delle performance di ogni server collegato al nostro sistema. Approfondirò questi aspetti nel prossimo paragrafo.
Una vista omogenea di tutte le metriche di performance rilevanti
Il secondo ingrediente chiave della soluzione next level performance monitoring di Würth Phoenix è la rappresentazione omogenea di tutte le metriche disponibili per ogni server che viene monitorato.
È possibile navigare fra macchine SQL, AOS, CITRIX e altri ancora, trovando i dati rilevanti rappresentati in modo omogeneo, nonostante provengano da fonti tra loro molto diverse. Non servirà preoccuparsi dunque, di considerare il formato e la provenienza dei dati per effettuare un’analisi consistente, ma sarà possibile analizzare direttamente le metriche memorizzate. Tale rappresentazione omogenea permette inoltre di analizzare in tempo reale l’andamento delle performance. Eventuali variazioni risultano visibili e attraverso lo zoom multi-measure ci si può muovere attraverso le diverse metriche del sistema e paragonare le metriche classiche con le disk operations.
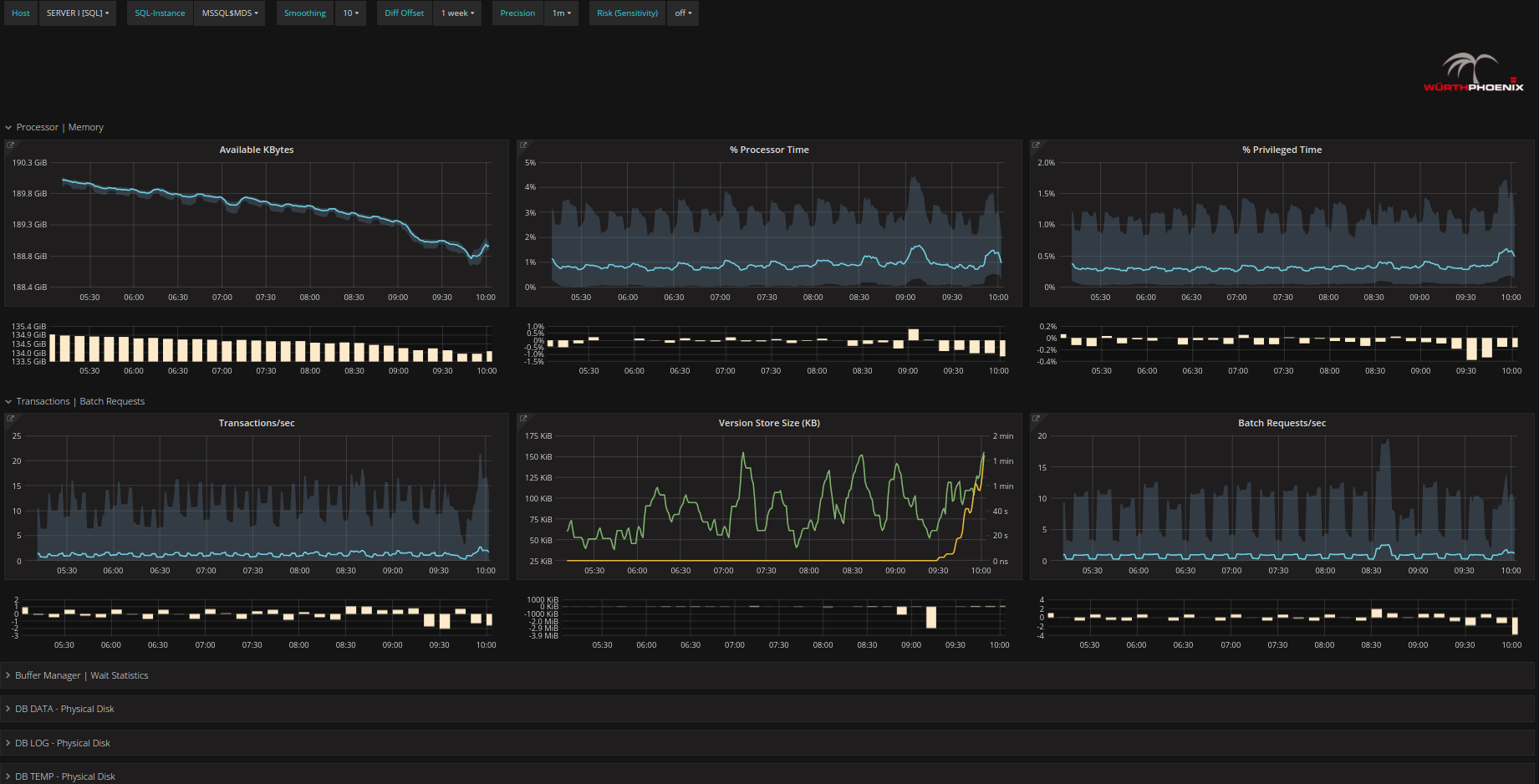
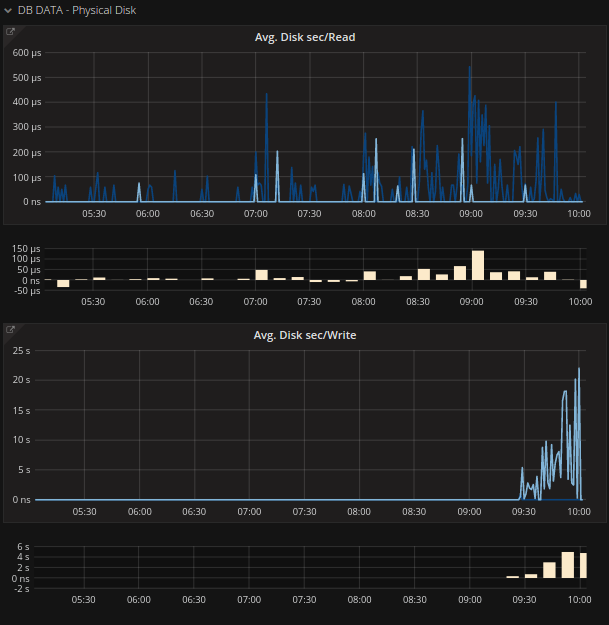
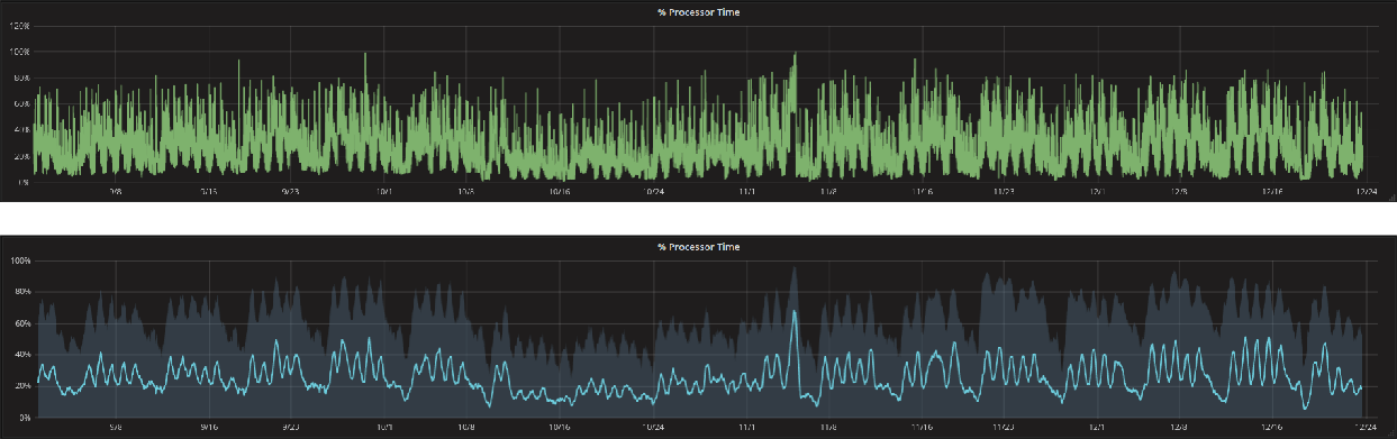
Metriche di performance piu’ trasparenti
Una delle features principali della rappresentazione di metriche in modo omogeneo è il grafico rappresentante una curva con i l’indicazione del range di valori che essa assume. Questa rappresentazione rende molto semplice interpretare l’andamento delle metriche e permette di capire esattamente cosa sta succedendo nel sistema analizzato.
Combinazione dati attuali con dati storici
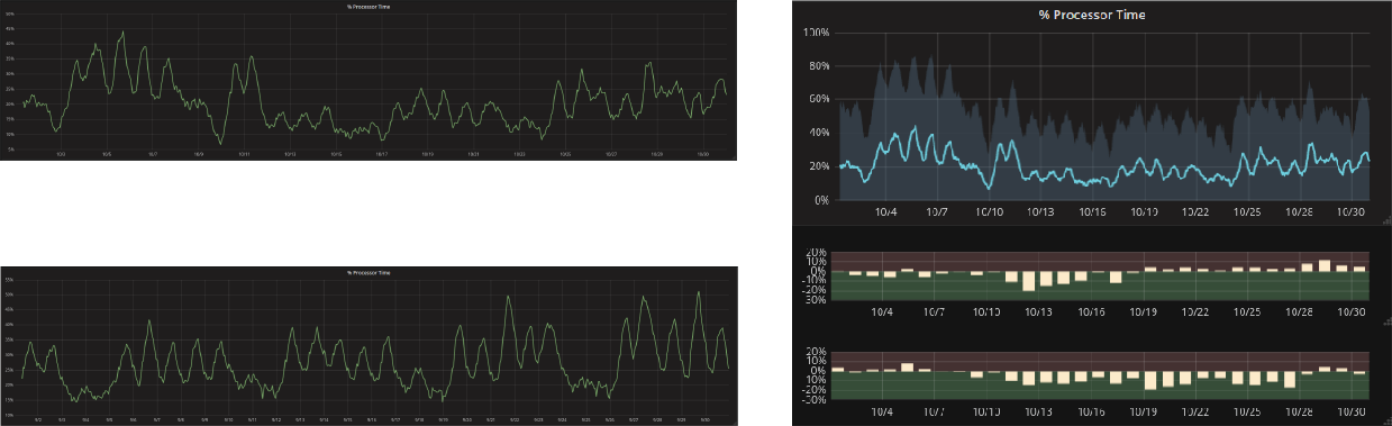
Ogni evento ha il proprio impatto sul sistema e quando si introduce un cambiamento, o succede qualcosa di nuovo, l’unico modo per poter quantificarne l’impatto è confrontare le metriche con quelle registrate prima che la modifica avvenisse. Tale analisi solitamente avviene effettuando il confronto tre le curve relative ai due intervalli temporali. La soluzione proposta da Wuerth Phoenix permette di confrontare in tempo reale i dati registrati in passato, non più sotto forma di curva, ma direttamente proponendo lo scarto rispetto ai valori attuali. In questo modo diventa più facile quantificare gli effetti e interpretarli senza dover consultare dati storici in maniera esplicita.
Il miglior supporto dello esperto umano: piu’ veloce, piu’ accurato, un’unico posto
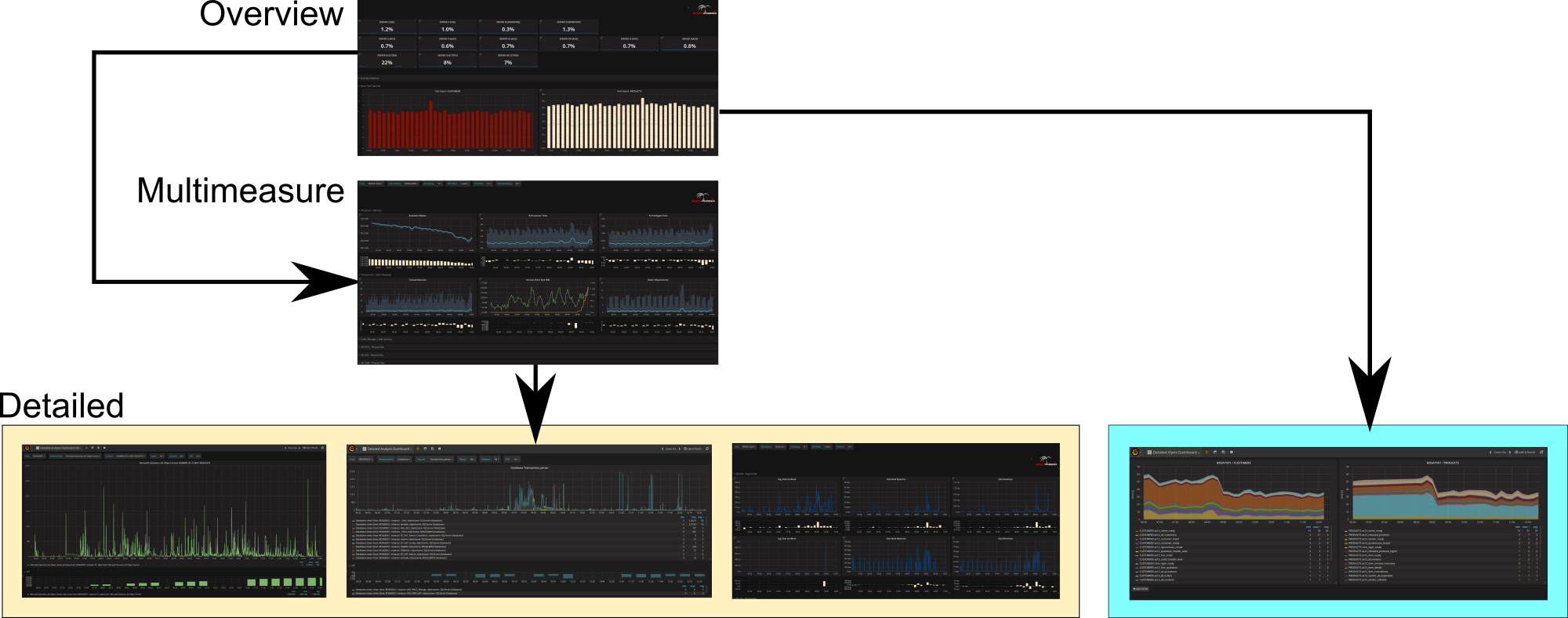
Come avrete intuito leggendo quando descritto in precedenza, il nostro obiettivo non è quello di sostituire l’analisi effettuata da esperti. Quello che noi desideriamo fare è creare un tool che sia per loro di supporto nell’analisi delle performance di rete. Il nostro obiettivo è quello di permettere ai tecnici di risparmiare tempo nella ricerca dei problemi, grazie ad una dashboard centralizzata che permette di tenere sotto controllo l’intero sistema, senza dover ricercare il malfunzionamento in ogni singolo componente. Gli esperti potranno così concentrarsi sulla risoluzione del problema, più che nella ricerca della causa.
La nostra soluzione propone tre livelli di dashboard: una high-level per una veloce presa visione del sistema, la multi-measure riportante i dati in modo omogeneo per le metriche più rilevanti e poi il livello più dettagliato che permette di analizzare la singola metrica.
Ritenete che questa soluzione calzi a pennello per voi? Per avere maggiori informazioni a riguardo non esitate a contattarci e non perdete il prossimo blog nel quale vi parlerò del ruolo del machine learning e del riconoscimento di anomalie nella nostra soluzione.

Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential