

Il server Microsoft Exchange è uno dei più diffusi sistemi di posta elettronica in ambito aziendale e spesso risulta un oggetto difficile da monitorare: tante volte i controlli implementati si limitano alla verifica della disponibilità del server in rete.
Dalla versione 2013 di Exchange è stato fatto un passo in avanti: infatti Microsoft ha messo a disposizione una serie di URL (Healthcheck URL) per verificare l’effettiva disponibilità dei servizi esposti verso i client.
Gli indirizzi hanno tutti una struttura simile del tipo:
https://<External FQDN>/<protocol>/healthcheck.htm
Dove il nome del protocollo corrisponde a:
- OWA Outlook Web App
- ECP Exchange Control Panel
- OAB Offline Address Book
- AutoDiscover il processo di Autodiscover
- EWS Exchange Web Services (Mailtips, Free/Busy, Lync clients, Outlook for Mac)
- Microsoft-Server-ActiveSync Exchange ActiveSync
- RPC Outlook Anywhere
- MAPI MAPI/HTTPS (da Exchange 2013 SP1)
Un controllo periodico di queste URL offre quindi la possibilità di verificare il funzionamento dei moduli del server, ma non aiuta a capire se ci sono degradi di performance e accodamenti.
Per un controllo più accurato, occorre necessariamente ricorrere ad un agent installato localmente sul server Exchange: utilizzandone uno che interroghi con una certa frequenza i dati di performance (Performance Counters) già esposti da Exchange, si evita di appesantire il server con frequenti richieste estemporanee che potrebbero portare ad ulteriore degrado del servizio.
La soluzione integrabile in NetEye
La soluzione di monitoraggio specifica per Exchange integrabile in NetEye utilizza tre diverse componenti, tutte Open Source:
- Telegraf per collezionare i dati di performance del server Exchange
- InfluxDB per memorizzare questi dati e storicizzarli
- Grafana per creare una Dashboard che presenti all’amministratore i dati significativi
Telegraf è un agent molto leggero da installare sul server Exchange in grado di leggere con una certa frequenza configurabile (normalmente 5 secondi) i dati di performance esposti da Windows e di inviarli via rete ad un database InfluxDB remoto. L’agent è in grado di mantenere anche un buffer locale in modo da non perdere dati in caso di temporanei problemi di collegamento con il database.
InfluxDB è un database ottimizzato per storicizzare metriche nel tempo, permettendo un accesso veloce ai dati durante la fase di analisi.
Grafana permette di creare delle Dashboard navigabili dove vengono presentati i dati di monitoraggio su pannelli diversi, correlati in base alla finestra temporale di interesse.
Sia InfluxDB sia Grafana sono già componenti standard di NetEye a partire dalla versione 3.9.
Gli oggetti da monitorare per controllare le performance
Per un server Exchange è importante tenere sotto controllo una serie di metriche diverse che complessivamente evidenziano il funzionamento generale.
Le code di messaggi: ci potrebbero essere degli accodamenti dovuti a flussi di Spam, attività anomale degli utenti (es. Auguri di Natale), o banalmente problemi di connettività verso Internet.
Inoltre bisogna verificare la latenza di accesso all’Active Directory perché questa facilmente potrebbe generare dei rallentamenti o dei problemi più gravi al server Exchange.
Lato utente possono essere seguiti i dati relativi all’ActiveSync (quindi tipicamente l’accesso degli Smartphone), Outlook Web Access (la posta via web), e l’RPC (tipicamente l’accesso di Outlook).
Per quanto riguarda OWA bisogna dire che in Exchange 2016 ci sono dei problemi nella generazione di queste metriche e non sempre sono disponibili / attendibili. Speriamo che Microsoft risolva presto il problema. In alternativa si può ricorrere ad un’analisi dei dati di IIS: .NET e ASP.
Lato Database di posta è importante tenere sotto controllo la frequenza di generazione dei file di log su disco in modo da evidenziare anomalie rispetto alla media, insieme al numero di sessioni che accedono nel tempo ai vari database.
Legato ai database c’è la cache che Exchange mantiene in memoria: un basso valore di corrispondenza (Hit Count) facilmente evidenzia un problema di carenza di memoria del server, oltre a causare rallentamenti.
Ultimo, ma non ultimo, l’accesso ai dischi dove sono posizionati i database: in caso di latenza eccessiva, si generano effetti negativi su molti livelli.
Grafana permette quindi di presentare in un’unica Dashboard questi valori, segnalando i picchi e i valori fuori norma nel periodo di osservazione.
I pannelli sono sincronizzati in modo da avere una visione puntuale dei vari oggetti nei momenti critici.
Ad esempio, una visione ad ampia scala, evidenzia già a prima vista l’andamento generale:
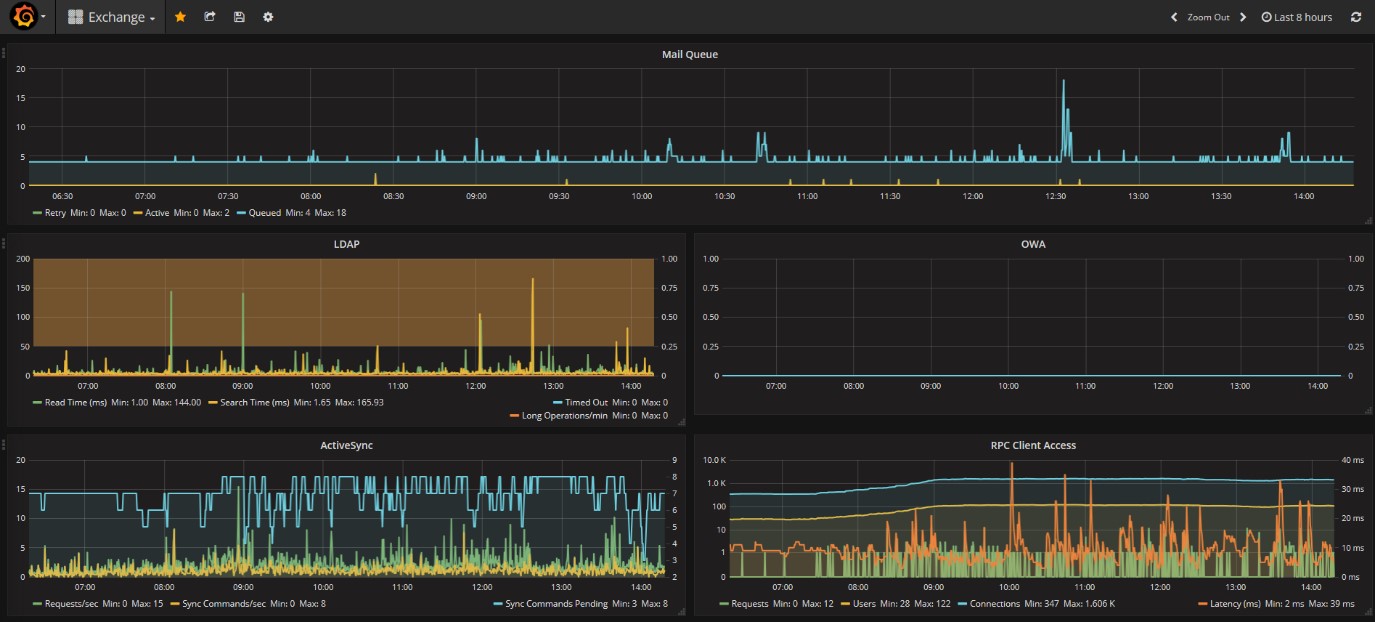
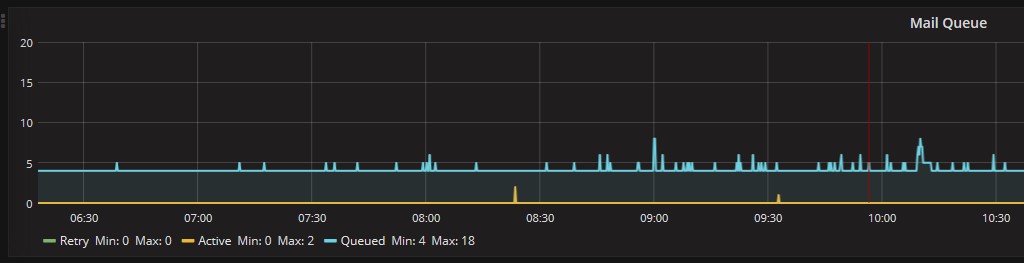
Andando un po’ in dettaglio sui singoli oggetti si vedono le code dei messaggi nel tempo, in questo caso nella norma:
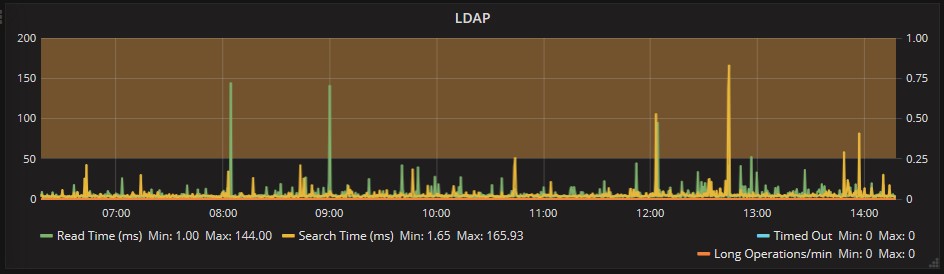
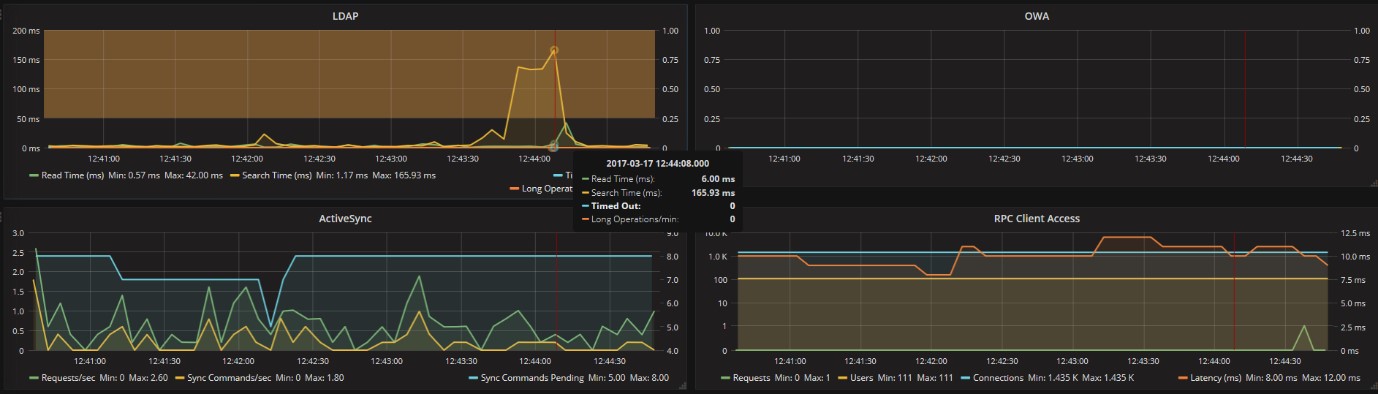
Insieme agli accessi LDAP all’Active Directory. Nell’esempio qui sotto in alcuni momenti ci sono state delle risposte un po’ lente nelle ricerche, ma non ancora critiche:
Lato ActiveSync non ci sono accodamenti preoccupanti nel periodo in esame:
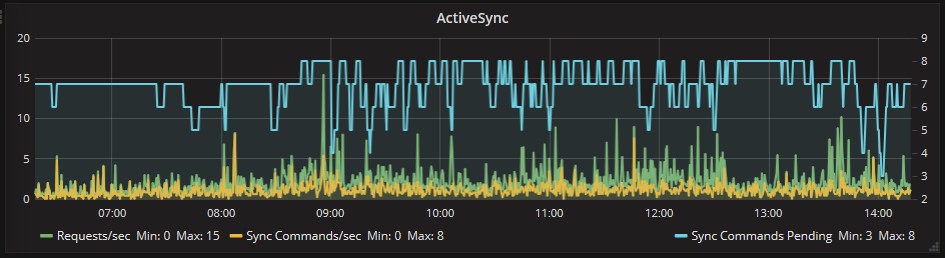
Anche per RPC (Outlook) il server risponde correttamente a fronte delle connessioni:
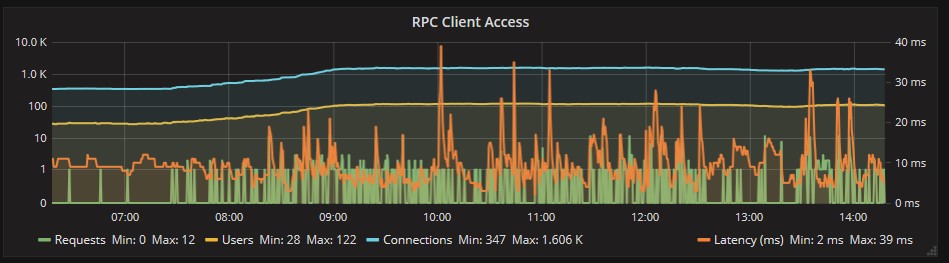
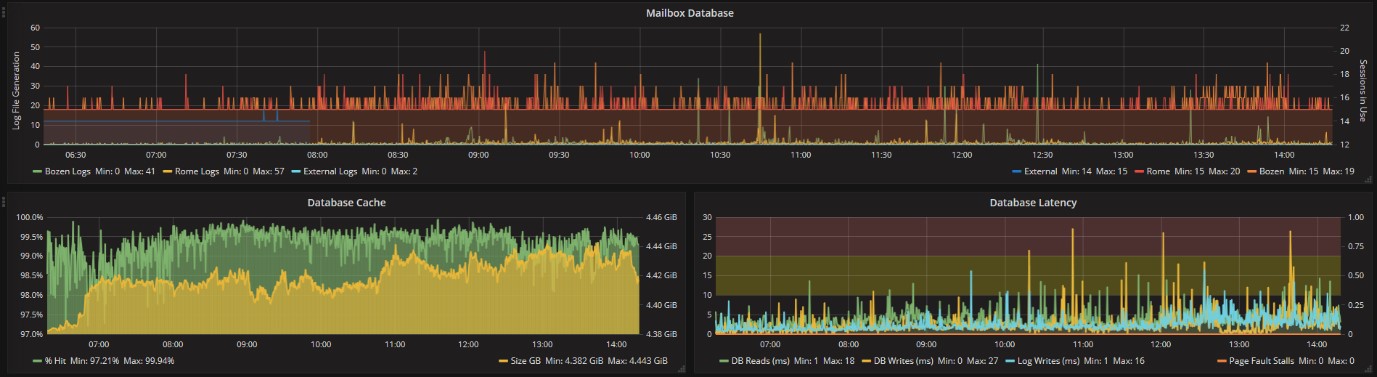
Per i tre Database di posta oggetto di questo esempio, la frequenza di generazione dei log si mantiene su valori normali senza picchi anomali di sessioni:

La cache in memoria viene utilizzata bene dal server Exchange, segno che non ci sono problemi di mancanza di RAM:
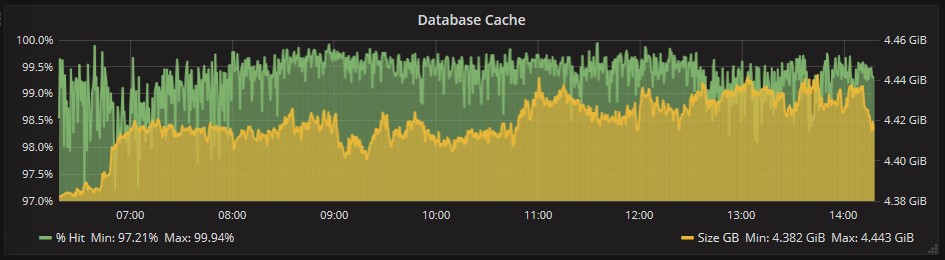
L’unica nota di attenzione l’abbiamo dal lato dell’accesso ai dischi, dove si vede qualche rallentamento per fortuna solo in qualche momento sporadico:
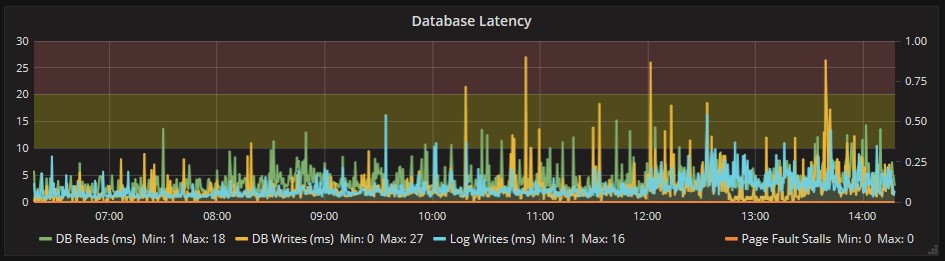
Non ci sono blocchi (Stalls), ma i valori da tenere più controllati sono quelli relativi alla lettura del DB da disco e la scrittura dei Log.
Volendo verificare i dettagli, ad esempio di un picco sull’accesso LDAP, è possibile restringere la finestra di analisi ad un intervallo di tempo ridotto per vedere se un problema in un componente, ha generato dei disservizi o è stato causato da carichi anomali in qualcun altro.
Conclusione
Ovviamente le metriche basilari evidenziate in questo esempio rappresentano un punto di partenza per scegliere opportunamente quelle da tenere controllate su un server Exchange.
Questa Dashboard può essere estesa e personalizzata in base alla configurazione specifica dell’architettura presente presso un’azienda, includendo ad esempio nello stesso pannello dei dati provenienti dal servizio Antispam / Mail Relay.






