
30. 12. 2024
Alessandro Taufer
DevOps, Log-SIEM
Optimizing Log Collection in Kubernetes/OpenShift with Elastic Stack
When monitoring Kubernetes clusters using Elastic Stack, the volume of logs can be overwhelming, often reaching gigabytes per minute. This is particularly true for OpenShift clusters, where significant traffic originates from system namespaces you might not be familiar with.
Optimizing log collection becomes crucial for maintaining system efficiency and resource utilization. Success in this endeavor relies heavily on implementing the right collection strategy and understanding which logs are truly valuable for your monitoring needs.
Understanding Log Sources
A systematic approach to log management starts with proper monitoring. While sophisticated tools aren’t necessary, one must-have is a basic dashboard which tracks two essential metrics:
- Namespace-specific log volume
- Node-specific log volume
These visualizations help identify:
- Anomalies in namespace log production
- Infrastructure issues (e.g., nodes not transmitting data)
- Potential system problems requiring investigation
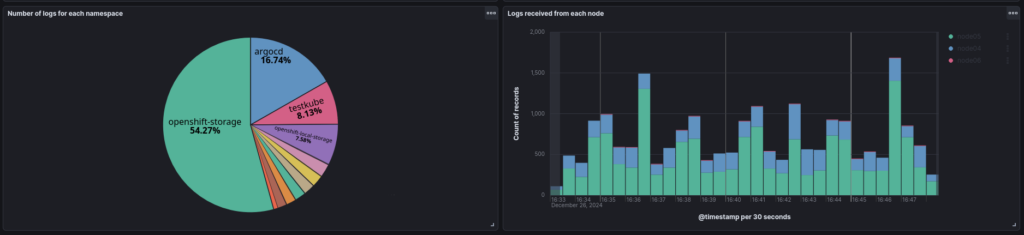
Remember that the primary purpose of observability is to provide clear insights into cluster operations. If you identify gaps in your monitoring coverage, don’t hesitate to implement additional visualizations that address them.
Adjust Application Verbosity
Once you’ve identified the namespaces and applications generating the highest volume of logs, you can begin the optimization process.
Start by evaluating the necessity of all logging outputs. Are all current logs essential? If yes, focus on retention policies. If no, consider reducing application verbosity.
An often overlooked aspect of log management is adjusting application verbosity levels. Default settings rarely align with specific organizational needs, making this adjustment crucial for optimal log management.
The process of modifying verbosity levels is typically straightforward. Consult the application’s documentation, locate the configuration file (usually in YAML format), and adjust the related setting with a simple line edit.
Implement Log Filtering
In certain scenarios, you may encounter limitations or specific requirements when managing log verbosity:
- Applications that don’t support verbosity adjustments
- Multiple monitoring systems requiring different verbosity levels
- Need to monitor only specific cluster log subsets
The Elastic Agent offers a solution through its processors configuration in the integration policy. The following configuration demonstrates how to exclude monitoring namespaces and specific pod logs:
- drop_event:
when:
or:
- equals:
kubernetes.namespace: openshift-monitoring
- equals:
kubernetes.namespace: monitoring
- regexp:
kubernetes.pod.name: "openshift-pipelines-operator-*"This example of processor configuration will:
- Exclude logs from the
monitoringnamespaces - Remove logs from pods matching the pattern
openshift-pipelines-operator-*
The processors feature offers extensive capabilities beyond this example. For comprehensive information about available processors and their configurations, consult the related docs.
Conclusions
To maintain the effective operation of your Elastic cluster’s log ingestion, it’s important to carefully apply and adjust these optimization steps according to your specific requirements. As you tailor these strategies, it’s advisable to err on the side of caution – when unsure about certain log entries, retaining them is generally the best approach to prevent the loss of potentially valuable information.
If you find that these optimization steps have not sufficiently reduced your log volume, it may be beneficial to consider implementing custom log retention policies. This is a topic that I’ll explore further in a future post.
Interested in more readings about monitoring OpenShift? You might find this article useful!
These Solutions are Engineered by Humans
Are you passionate about performance metrics or other modern IT challenges? Do you have the experience to drive solutions like the one above? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles just like this as well as other roles here at Würth Phoenix.






Author
Latest posts by Alessandro Taufer
31. 12. 2024
Development, DevOps
Tips for Writing Efficient Python Code