
My colleague Daniel has already described a concrete case in which he used ES|QL. Moved by curiosity I decided to attend an Elastic webinar on ES|QL, and I discovered some interesting things that I’d like to share with those of you who like using Elastic.
Elastic provides several possible ways to do searches. Current query languages create a complex experience for practitioners.
Elasticsearch Query Language (ES|QL) is Elasticʼs new piped language and query engine that transforms, enriches, and simplifies data investigations. The new ES|QL query engine delivers advanced search capabilities with concurrent processing, improving speed and efficiency irrespective of data source and structure. It lets you accelerate resolution by creating aggregations and visualizations from one screen, delivering an uninterrupted workflow.
This new query language was introduced in NetEye version 4.37 in which we introduced Elastic version 8.14.
Below are its key benefits:
- Greater query speed
- Simplified Elasticsearch
- New transformative search engine
- Improved alerting
- Fast time to insights
The increased query speed is provided through these improvements:
- No transpilation or translation
- Queries are parsed and optimized for distributed execution
- It operates in blocks, instead of one row at a time
- It takes advantage of specialization and multi-threading
- Benchmarking shown ES|QL can outperform DSL in many instances
ES|QL is faster than Elasticsearch aggregations in some cases, even without many optimizations.
Now let’s look at ES|QL Features:
- Both unstructured and structured data
- Procedural piped language
- SQL-like filtering and data manipulation
A Piped Query Language was used because pipes are routinely used in Unix/Linux and because there are already other similar languages in other market products that have been very successful:
- Splunkʼs Search Processing Language (SPL)
- Microsoftʼs Kusto Query Language (KQL)
- Amazonʼs CloudWatch queries
Now let’s see how this language offers benefits within the three pillars of Elastic Stack.
In search, developers will benefit from a simplified coding and querying experience with ES|QL, saving time and reducing cost with these efficiencies.
ES|QL delivers a simple way of understanding more about your data: what it contains, how it should be organized, and how to troubleshoot when issues arise, all again saving time and reducing cost.
ES|QL streamlines tasks into one query which can be concurrently processed for even faster performance, providing a lower TCO, and thus more for less.
In observability, using ES|QL greatly simplifies the analysis of metrics, logs, and traces from a single query, quickly identifying performance issues, all from a single search box. You can define fields on the fly, enrich data with lookups, and process queries concurrently, for speed and efficiency.
Integrating ES|QL with Elastic ML and AiOps improves detection accuracy along with aggregated value thresholds.
And finally, for security, ES|QL enhances SecOps by streamlining workflows and investigations: providing a singular place to find what you are looking for. Pull in critical context for investigations with ES|QL lookups, and enrich data and defining fields on the fly for valuable insights for accelerated action.
ES|QL reduces alarm fatigue and ensures more accurate alerts by incorporating aggregated values in detection rules.
Currently, this query language still has limitations (and note that it’s still under development):
- Full-text search — keyword-based queries only
- Some field types are not yet supported
- Time series data streams are not supported
More detail can be found here.
But where/how can we use this new query language?
ES|QL in Discover
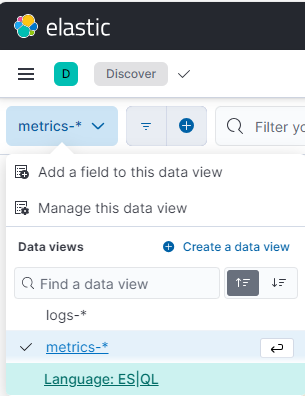
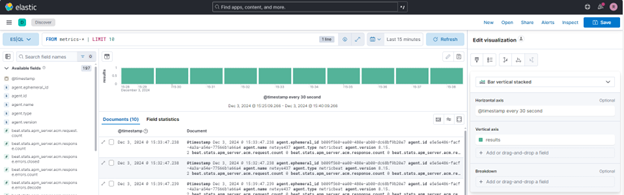
ES|QL Alerting in Discover

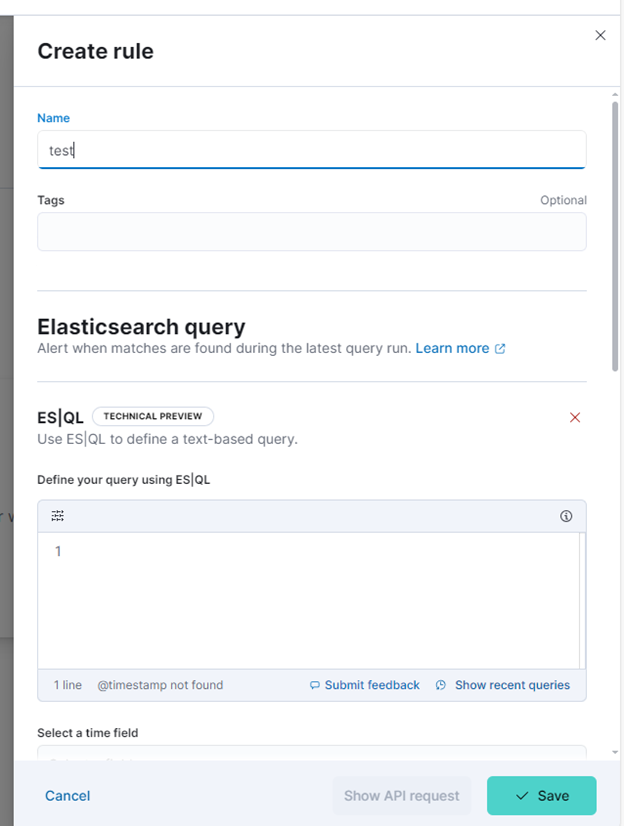
ES|QL Detection Rule in Security
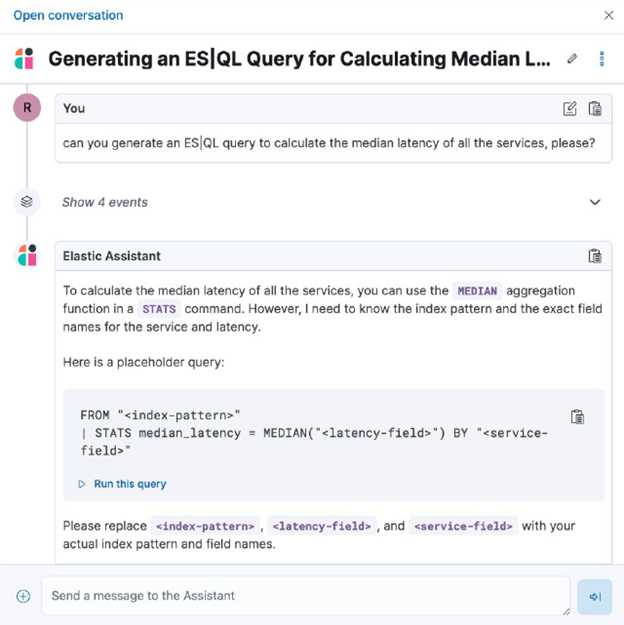
ES|QL AIOps (for those clients who have Elastic Enterprise)
ES|QL Syntax
Now let’s move on to understanding the ES|QL Syntax:
source-command
| processing-command1
| processing-command2
An ES|QL query is comprised of a series of commands connected together by pipes.
- Source commands retrieve or generate data in the form of tables
- Processing commands take a table as input and produce a table as output
- You can chain processing commands, separated by a pipe character
|where each processing command works on the table output of the previous command
Here an example command:
POST /_query
{
"query": """
FROM library
| EVAL year = DATE_TRUNC(1 YEARS, release_date)
| STATS MAX(page_count) BY year
| SORT year
| LIMIT 5
"""
}
To return results formatted as text, CSV, or TSV, use the format parameter:
POST /_query?format=txt
"columns": [
{ "name":
"MAX(page_count)", "type":
"integer"},
{ "name": "year"
, "type": "date"}
],
"values": [
[268,
"1932-01-01T00:00:00.000Z"],
[224,
"1951-01-01T00:00:00.000Z"],
[227,
"1953-01-01T00:00:00.000Z"],
[335,
"1959-01-01T00:00:00.000Z"],
[604,
"1965-01-01T00:00:00.000Z"]
]
}
Here’s the list of Source Commands:
- from
- show
- row
And then we can talk about the Process Commands
- Processing commands take a table as input and produce a table as output
- You can chain processing commands, separated by a pipe character:
| - Each processing command works on the output table of the previous command.
Here is the list of Process Commands:
- dissect
- drop
- enrich
- eval
- grok
- keep
- limit
- mv_expand
- rename
- sort
- stats… by
- where
And here’s the ES|QL Functions Operators that create conditions out of boolean expressions, which can be formed using:
- Relational operators such as <,>,<=, = >, ==, and !=
- Boolean functions like
starts_with - Boolean expressions created with
eval liketo match strings using the wildcards ? and *- For example
“?*nˮmatches John and Ethan, but not Natalie
- For example
rliketo match strings using regular expressions- While computationally expensive,
rlikematches patterns such as timestamps and email addresses, etc., while(?<![0-9.+-1)(?>![+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))matches decimal numbers
- ES|QL uses a grok parser as shown previously
- While computationally expensive,
- The
inoperator tests whether a literal or a field/column are members of a list of literals/values - Boolean operators can be used in combination using,
and,or, andnot
There are too many to cover today, so please refer to the ES|QL Functions Operators documentation.
There are different Functions categories:
- Aggregate functions
- Grouping functions
- Conditional functions and expressions
- Date and time functions
- IP functions
- Math functions
- Spatial functions
- String functions
- Type conversion functions
- Multi-value functions
The most frequently used Functions categories are ES|QL Functions String Functions.
Here’s an example to clarify my first and last name 😊
row first_name = "Franco", last_name = "Federico", roles = "System Architect”, product = "NetEye"
| eval full_name = concat(first_name, " ", last_name)
| eval roles = split(roles, ",")
| eval trim(product)
| keep full_name, roles, product

ES|QL Functions Date Functions
row date_string = "2024-12-03"
| EVAL date1 = DATE_PARSE("yyyy-MM-dd", date_string)
| eval date2 = date_format("yyyy/MM/dd", date1)
| eval truncted_date1 = date_trunc(1 year, date1)
| eval year = date_extract("year", date1)
| keep date1, date2, truncted_date1, year

ES|QL Functions Conversion Functions
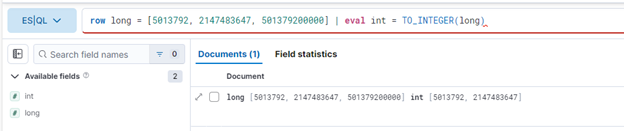
row long = [5013792, 2147483647, 501379200000]
| eval int = TO_INTEGER(long)
If you’ve gotten this far, I want to give you a quick spoiler – something I discovered while talking to other Elastic guys. ES|QL will replace all other Elastic scripting languages (which will gradually be abandoned).
These Solutions are Engineered by Humans
Did you find this article interesting? Are you an “under the hood” kind of person? We’re really big on automation and we’re always looking for people in a similar vein to fill roles like this one as well as other roles here at Würth Phoenix.






Franco Federico
Hi, I’m Franco and I was born in Monza. For 20 years I worked for IBM in various roles. I started as a customer service representative (help desk operator), then I was promoted to Windows expert. In 2004 I changed again and was promoted to consultant, business analyst, then Java developer, and finally technical support and system integrator for Enterprise Content Management (FileNet). Several years ago I became fascinated by the Open Source world, the GNU\Linux operating system, and security in general. So for 4 years during my free time I studied security systems and computer networks in order to extend my knowledge. I came across several open source technologies including the Elastic stack (formerly ELK), and started to explore them and other similar ones like Grafana, Greylog, Snort, Grok, etc. I like to script in Python, too. Then I started to work in Würth Phoenix like consultant. Two years ago I moved with my family in Berlin to work for a startup in fintech(Nuri), but the startup went bankrupt due to insolvency. No problem, Berlin offered many other opportunities and I started working for Helios IT Service as an infrastructure monitoring expert with Icinga and Elastic, but after another year I preferred to return to Italy for various reasons that we can go into in person 🙂 In my free time I continue to dedicate myself to my family(especially my daughter) and I like walking, reading, dancing and making pizza for friends and relatives.
Author
Latest posts by Franco Federico
09. 09. 2025
NetEye
Backing up a MariaDB Galera Cluster
12. 06. 2025
NetEye, Unified Monitoring
From Monitoring to SOC
17. 02. 2025
Unified Monitoring
Monitoring Printer Logs