





12. 12. 2022
NetEye, Unified Monitoring

19. 12. 2024
Attilio Broglio
Unified Monitoring
How to Monitor MSSQL in a Synchronized, High-availability Setup
This article describes an ad-hoc monitoring solution for MSSQL within a synchronized high-availability setup. Due to the circumstances surrounding the request from a customers’ request, with this setup we couldn’t use the standard command/check that’ are’s commonly used, but an additional layer was required to manage the resources involved.
Use Case
The behavior of MSSQL in a synchronized, high availability environment can be understood by looking at this schema:
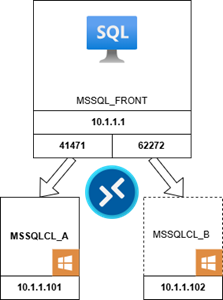
In a synchronized high-availability setup, both appliances (MSSQLCL_A and MSSQLCL_B) are actively kept in sync. The secondary node is always available and can take over in case of a failover: while the primary node handles requests, the secondary node is in a ready state to take over seamlessly if needed. So when a failover occurs, the appliance is switched from the DB being hosted in MSSQLCL_A (@ port 41471) to being hosted in MSSQLCL_B(@ port 62272).
When an instance goes DOWN on a host, the configuration above allows for switching the service to another instance on another host, using the same VIP-IP, but with a different port. So if the check (i.e. check_mssql_health) continues to use the broken instance with the outdated port, it throws up a CRITICAL even if the instance is UP, but on another node. Moreover, once the new instance goes DOWN, then it may change the port again when restored, and so the updated check will also look at the wrong port.
So there are mainly two problems:
- On Host DOWN the script/check must be able to switch the check to the secondary PORT
- On Host UP after a failure, the configured PORT on the check must be updated
None of these points is covered by the actual script check_mssql_health, and neither BP (Business Process) nor other solutions provide this dynamicity. So we decided to combine:
- A wrapper script for managing appliance-port switching
- An automation for updating the ports of services
Wrapper for check_mssql_health
The wrapper check_mssql_health_ha.sh, built on top of the well-known check check_mssql_health, manages the port change when a Host goes DOWN. This script, in addition to all the standard check_mssql_health arguments, is configurable with 2 additional custom variables:
mssql_health_port1mssql_health_port2
When called, it looks for the active port out of the two ports passed as arguments. If neither of these ports is available, it raises a CRITICAL alarm. If a “listening port” is found, it passes the port to the check_mssql_health.pl script, which calls the working DB instance.
Automation for check_mssql_health
The Icinga automation, based on IMPORT_server_mssql_ha and SYNCH_server_mssql_ha, provides the dynamicity for changing the port on the services when an appliance is restored after a DOWN and then listening to a new port. This automation is fed by a CSV file, provided daily by the customer, that’s parsed and used as datasource in order to update Icinga with this “new“ data.
Let’s look at that flow in more detail.
Icinga configuration
The structure inside Icinga is based on this command: mssql_health_ha and uses this BASH script:
/neteye/shared/monitoring/plugins/check_mssql_health_ha.shA Service Template called generic-mssql-ha uses this command, and is then used as a “parent” for all services. In order to speed-up the configuration process, the Service Set “Windows_MSSQL-HA” is used.
This SS is composed of these services:
- MSSQL(HA) Database Free Space
- MSSQL(HA) Database Log Free Space
- MSSQL(HA) Backup Age in Hour
- MSSQL(HA) Number of free-list-stalls per Sec
- MSSQL(HA) Memory Pooldata Buffer Hitratio
- MSSQL(HA) Number of SQL Initcompilations per Sec
- MSSQL(HA) Number of SQL Recompilations per Sec
- MSSQL(HA) Number of Deadlocks per Sec
- MSSQL(HA) Number of AVG latches wait Time
- MSSQL(HA) Number of latches waits per Sec
- MSSQL(HA) IO Busy
- MSSQL(HA) Full Batch Requests per Sec
- MSSQL(HA) Full Transactions per Sec
- MSSQL(HA) Database Failed Jobs last Hour
- MSSQL(HA) Database Number of connected Users
- MSSQL(HA) Database Number of Locks Waits
- MSSQL(HA) Database Status
- MSSQL(HA) CPU Busy
- MSSQL(HA) lacy writes
- MSSQL(HA) List DBs
- MSSQL(HA) Database Data Free Space
Then an ad-hoc Host Template wp-ht-server-agent-windows-sql-always-on-instance inherits all these services from the Service Set. To configure it, a user must set the proper arguments just as when he or she creates the Host:
- mssql_health_username
- mssql_health_password
- mssql_health_port1
- mssql_health_port2
To make everything automatic, an import rule (IMPORT_server_mssql_ha) and a sync rule (SYNCH_server_mssql_ha) have been created.
- IMPORT_server_mssql_ha: This rule reads all rows in the csv-file
/neteye/shared/httpd/file-import/external/server_mssql_ha.csvand prepares the data for the sync rule. This file should be built with this structure:
| Hostname | mssql_front.wp.net |
| Host | MSSQL_FRONT |
| Hostname1 | mssqlcl_a.wp.net |
| Host1 | MSSSQLCL_A |
| Host1_IP | 10.1.1.101 |
| Host1_Port | 41471 |
| Hostname2 | mssqlcl_b.wp.net |
| host2 | MSSALCL_B |
| Host2_IP | 10.1.1.102 |
| Host2_Port | 62272 |
- SYNCH_server_mssql_ha: This rule creates/updates the MSSQL host inside Icinga and, as the import rule, can be scheduled in order to keep all data updated.
Conclusion
Thanks to the solution based on this wrapper and the automation, it was possible to cover this use case, ensuring the monitoring of an MSSQL in synchronized high-availability. If you need any information or details on the implemented wrapper please don’t hesitate to contact us.