
Hi all, it’s been a while. I’m deeply sorry not to have sent out some blog posts lately, so now I’ll try to get back your trust by providing some useful information.
Not only that, I’ll even go out of my comfort zone: instead of NetEye Core and monitoring strategies, I’ll talk about NetEye SIEM and Elasticsearch. My recent experiences in managing NetEye Cloud Service have forced me to get to know a bit of the underlying mechanisms that govern Elasticsearch.
And so here we are, talking about Disk Watermarks. Or, if you prefer: How to prevent the Elasticsearch Rebalancing Process from filling up all your disk space and crashing. Because I recently had to bang my head on my monitor while trying to understand why Elasticsearch stubbornly keeps moving shards onto a Cluster Node that is already at its limit. Now, you might say to yourself “okay, Elasticsearch nearly fills up all the available disk space, so what?”.
Well, when this happens, almost any operation performed by Elasticsearch stops and fires off all kinds of Exceptions with “No space left on device” as the primary cause. And then the Elasticsearch Node stops working, going out of Cluster and forcing Shard Recovery on all remaining nodes that, in turn, might exhaust their available disk space and so on, literally making your Cluster crumble like a sand castle in a rising tide. Not very funny, right?
To avoid this kind of scenario, Elasticsearch recently introduced several settings to manage what they call Disk-based shard allocation (you can find more details at https://www.elastic.co/guide/en/elasticsearch/reference/8.14/modules-cluster.html#disk-based-shard-allocation). This process can become quite complicated, so let’s simplify what it does and look at the most important settings.
Elasticsearch as a Water Storehouse
First of all, you have to imagine your data as streams of Water, and your Elasticsearch Cluster as a Storehouse with several Pools inside, each Pool managed by a man in a Blue Uniform. Water must rest for different purposes, and each purpose needs a different amount of rest time, therefore Pools are divided into different Resting Groups.
Water comes in from one or more Streams and each Stream enters the Storehouse towards one Pool. Blue Uniforms cooperate to manage Water distribution between available Pools. They have three different ways to do it:
- Stop the incoming Streams of Water
- Use Tanks to move Water from a Pool to another one
- Use Tanks to remove Water and throw it out of the Storehouse
- Note that each Tank used has a different size from the others.
The goal of the Blue Uniforms is obviously to avoid Water spilling out from a Pool and flooding the whole Storehouse. If a Pool does flood, its Blue Uniform can close the Pool by keeping it fenced, but this happens at the cost of divvying up the Water from the closed Pool into the remaining Pools in the same Resting Group. And also, the Blue Uniform is out of commission until its Pool is reopened again.
This is a pretty good analogy about how Elasticsearch works. Now let’s just substitute some concepts:
- Water is your data
- The Storehouse is your Elasticsearch Cluster
- Each Pool and its Blue Uniform is a Cluster Node:
- The Pool is the disk space available to Elasticsearch Service
- The Blue Uniform is the Elasticsearch Service itself
- Each Tank is a Shard (and this is why each Tank has a different size)
- Resting Groups are your Data Layer (HOT, WARM, COLD, FROZEN)
Given that, you can see Elasticsearch as a series of processes busy filling Shards with data and moving them around all Cluster Nodes.
What Elasticsearch Does to Prevent Flooding
As you might have guessed by now, Water is not necessarily flowing into a Pool with a continuous and constant flow: if you move a Tank of Water from one Pool to another, you produce a big increase in the Water flow to the destination Pool for a brief time; and since the Tank is a representation of a Shard, this operation cannot be interrupted half-way: the Blue Uniform must pour all the Water from the Tank into the Pool.
Well then, what could cause a flood? If water comes into a Pool in a single stream or Tank, it’s possible to easily understand if the current operation will make the Pool flood or not and block it. But we’re talking about a highly parallelized Cluster where each Cluster Node can start more than one Shard relocation operation, and several operations can overlap, even targeting the same Cluster Node as the joint destination.
In this scenario, determining if the Pool will flood and which operation must be stopped can become resource-consuming, so the easiest thing to do is check the Water level in the destination Pool in advance.
To be more flexible, we can define two Thresholds: a Low Threshold and a High Threshold. Of course, both of these thresholds must be lower than the edge of the Pool, known as the Flooding Threshold. Mathematically speaking, we have low < high < flooding.
We can use these Thresholds to manage incoming and outgoing water for each Pool in the form of a normal stream (data ingestion), incoming Tanks and outgoing Tanks.
Let’s name the Pool Water’s Level as L:
| Level of Water | Incoming stream | Incoming Tank | Outgoing Tank |
L < low | Allowed | Allowed | Allowed with low priority |
L > low, L < high | Allowed | Allowed | Allowed |
L > high, L < flooding | Allowed | Blocked | Allowed |
L > flooding | Blocked | Blocked | Allowed |
Let’s talk about it in Elasticsearch terms.
If the Level of Disk Space is below the Low Threshold, everything works normally: the current Cluster Node can process Ingestion and participate actively in Shard Relocation, but the Relocation Algorithm will most likely accept incoming Shards then move them out. The goal of the Relocation Algorithm is to fill more disk space, equally distributing data amongst all Cluster Nodes.
If the Level of Disk Space is above the Low Threshold but below the High Threshold, then the Relocation Algorithm increases the priority of outgoing Shard Relocation: even if incoming Shards are accepted, the number of outgoing Shards will increase. The Relocation Algorithm tries to prioritize reaching a Level below the Low Threshold, but this isn’t guaranteed to happen: data might still come in with a higher ratio than the outgoing Shards.
If the Level of Disk Space is above the High Threshold but below the Flooding Threshold, the Cluster Node goes into DefCon 2: even if Ingestion is still allowed, the Relocation Algorithm will not accept incoming Shards, but keeps moving Shards out. The goal of the Relocation Algorithm is to lower the Level below the Low Threshold as soon as possible. Yet, this is not guaranteed to happen: other Cluster Nodes might be in this same situation and unable to accept Shards from this node. But at this point the Elasticsearch Cluster is still performing normally.
If the Level of Disk Space is above the Flooding Threshold, the Cluster Node foes into DefCon 1: even Ingestion is stopped, placing the Node in a sort of read-only state. This is a serious and tricky case of dysfunction, because only part of Ingestion is blocked. The Elasticsearch Cluster can still perform its work, but no new data are coming in to the Shards on this Cluster Node. Yes, there is still the replica, but you’re one step away from catastrophe.
The goal of the Relocation Algorithm is to lower the Level below the Low Threshold by moving out as many Shards as it can. Yet, this is not guaranteed to happen: other processes might write into the same partition (think about Elasticsearch Logs, which are usually in the same Data Partition), and if no Shard can be moved, Disk Space will inevitably be exhausted.
Note that, for reactivation of Ingestion and Shard Relocation, the most important threshold is the Low Threshold:
- If the Level goes over the Low Threshold, whatever the extent, incoming Shard Relocations will be reactivated only after the level goes below the Low Threshold again
- If the Level goes over the Flooding Threshold, Ingestion will be reactivated only after the level goes below the Low Threshold again
To keep it simple, going over the Low Threshold will put the Cluster Node in a warning state, disabling some functions based on the level reached. All disabled functions will be restored only when the level goes below the Low Threshold again.
These 3 thresholds are called the Disk Watermark in the Elasticsearch documentation.
Useful Considerations about Thresholds
This Disk Watermark setting is interesting and powerful, but you must tune it: Elasticsearch doesn’t consider the size of the Shard it wants to move, it just checks the current Disk Free Space Level against the Watermarks. So you have to be smart enough to set these thresholds right.
The first bit of information you need to collect is the size of your biggest Shard. Then, you have to ensure that relocating this Shard will not consume all available Disk Space on the Cluster Node that receives this shard. Assuming all your ILM and System Policies adhere to Elasticsearch Best Practices, you will never have Shards bigger than 50GB. Since your average node is able to receive at most 2 Relocating Shards at the same time (unless you’ve tuned it differently), you have to set the Low Disk Watermark to 150GB and the High Disk Watermark to 100GB (3- and 2-times max Shard Size respectively). In the worst case, with these settings your Cluster Node will have around 50GB of free space in a critical moment, and after a while it will have 100GB or more, leaving you plenty of time to assess the situation and take action.
About the Flooding Threshold: consider that if you reach this Level, the Cluster Node is most likely frozen, and the only thing that will grow in size in the Elasticsearch partition is the Elasticsearch Log. So, you can assume that 10GB should be a reasonable enough value.
Then, even if you set these values correctly, ensure you have more than what’s required by the Low Disk Watermark on all nodes: Operations that will change the size of a Data Layer (like moving a Cluster Node from one layer to another or removing a Node from the Cluster) will most likely destroy your Cluster. Example:
- You have a Cluster with 6 nodes
- You set the Low Disk Watermark to 100GB
- 4 Nodes (A, B, C and D) have 3.1TB of Disk Space
- 2 Nodes (E and F) have 6.1TB of Disk Space
- You have in total of 24.6TB of Disk Space, reduced to 24TB because of Disk Watermark
- You have 17.5TB of Data (~70% used) divided as follow:
- Nodes A and B have 2.5TB of data
- Nodes C and D have 3TB of data (full)
- Node E has 3TB of data
- Node F has 3.5TB of data
- You shut down Node F
In this case, you lose 6.1TB of Disk space, lowering the whole capacity from 24TB to 18TB, that is 500GB above the quantity you need to accommodate all Shards. Even if this might be OK for a short while, you should consider that Nodes A and B will become full quickly: only Node E can accept data, meaning no Replica will be created for newer Shards. But this is not the biggest issue.
While recovering from the loss of Node F, Elasticsearch will push allocation on Nodes A and B, surely going above the Low Disk Watermark, and most likely even above the High Disk Watermark. In this case, there is a change that A or B might exhaust Disk Space, making one of them crash. Then, in an attempt to recover from this situation, another Node might crash and you will lose the Cluster.
Long story short: make sure all servers in each Data Layer have similar Disk Space and don’t feel safe just because you are below the Low Disk Watermark: if you need to work on a Cluster Node, you need more than the space required to accommodate data from the node you are working on.
How to Get the Current Values of Watermarks
You can see the current values of your Disk Watermarks by querying the _cluster/settings endpoint. You can do it through Kibana Dev Tools or es_curl.sh. If the API Call doesn’t return any values, use the Elasticsearch documentation to get your default, or use include_defaults option.
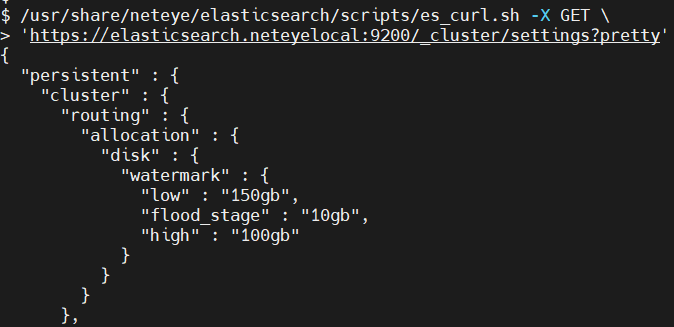
Then to set them, just PUT the settings you want using the tool of your choice.
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.






Author
Latest posts by Rocco Pezzani
18. 03. 2025
Icinga Web 2, ITOA, NetEye, UI, Unified Monitoring
A First Step towards Multitenancy in Icinga 2
31. 12. 2024
Business Service Monitoring, ITOA, NetEye, SLM, Unified Monitoring
Display a Service’s Availability with ITOA
30. 11. 2024
Business Service Monitoring, NetEye, Unified Monitoring
The Story of a Strange Business Process
15. 12. 2023
NetEye, Unified Monitoring
Troubleshooting Icinga Notifications