
Today we wanted to update our OpenShift cluster, and after a while we came up against the following error:
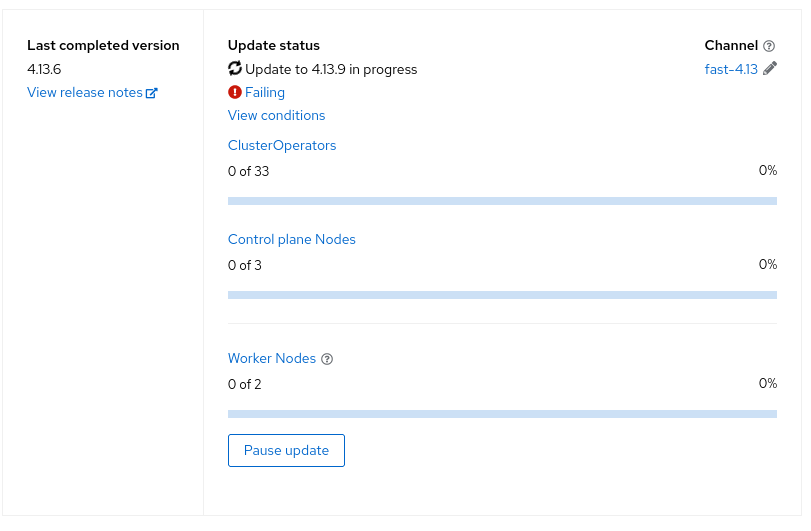
Not good…
Let’s start by checking the clusterversion to investigate if we can find any errors:
oc get clusterversion
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.13.6 True True 91m Unable to apply 4.13.9: an unknown error has occurred: MultipleErrors
By analyzing the logs further we found the following error:
oc get clusterversion -o yaml
[...]
- lastTransitionTime: "2023-08-25T13:55:14Z"
message: |-
Multiple errors are preventing progress:
* Cluster operator kube-apiserver is updating versions
* deployment openshift-etcd-operator/etcd-operator is not available MinimumReplicasUnavailable (Deployment does not have minimum availability.) or progressing ProgressDeadlineExceeded (ReplicaSet "etcd-operator-74cc7479b7" has timed out progressing.)
reason: MultipleErrors
status: "True"
type: Failing
it seems like the openshift-etcd-operator is not able to deploy the necessary pods. Let’s investigate it further and see which pods are running in the openshift-etcd-operator:
oc get pods -n openshift-etcd-operator
NAME READY STATUS RESTARTS AGE
etcd-operator-74cc7479b7-h8t64 0/1 CreateContainerError 0 97m
OK, what’s going on with the pod?
oc describe pod etcd-operator-74cc7479b7-h8t64 -n openshift-etcd-operator
[...]
Warning Failed 96m (x3 over 97m) kubelet (combined from similar events): Error: container create failed: time="2023-08-25T12:25:04Z"
level=error msg="runc create failed: unable to start container process:
unable to init seccomp: error loading seccomp filter into kernel: error loading seccomp filter: errno 524"
According to the RedHat release notes, it seems that the issue
is due to a CoreOS limitation in the number of seccomp profiles that can be created on the worker node.
and is related to the following bug: https://issues.redhat.com/browse/OCPBUGS-2637.
Bad news. It seems like a kernel bug related to the architecture amd64.
After some further searching we’ve been able to pin down the issue to the specific OpenShift version 4.13.6 https://issues.redhat.com/browse/OCPBUGS-16655.
The bug still isn’t solved, but at least there’s a suggested workaround that has to be run on all worker nodes:
sudo sysctl status net.core.bpf_jit_limit=364241152
After that, the update seems to be working again!






Lorenzo Candeago
DevOps Engineer at Würth Phoenix
Author
Latest posts by Lorenzo Candeago
30. 07. 2024
DevOps
Terraform Integration with Ansible
29. 07. 2024
DevOps
include_task vs import_task in Ansible
24. 07. 2024
DevOps
How to Add SSH Keys to ArgoCD and Tekton on OpenShift to Access Gitea: Part 3 – A Simple Tekton TaskRun
17. 07. 2024
DevOps
How to Add SSH Keys to ArgoCD and Tekton on OpenShift to Access Gitea: Part2 – Add an SSH Key as a Secret to ArgoCD and Run a Test Deployment
17. 07. 2024
DevOps
How to Add SSH Keys to ArgoCD and Tekton on OpenShift to Access Gitea: Part1 – Set up the Test Environment and Add SSH Key to Gitea