
In my previous blog-post I wrote an introduction to pipelining in OpenShift. This blog post is a follow-up to explain how to trigger a pipeline automatically.
Tekton triggers are quite complex and need some explanation in order to be understood. To trigger a pipeline you need several components. In the graph below you can see the components (marked in red) defined inside the Tekton Pipeline, while the Ingress loadbalancer (green) and Bitbucket (blue) are components external to Tekton.
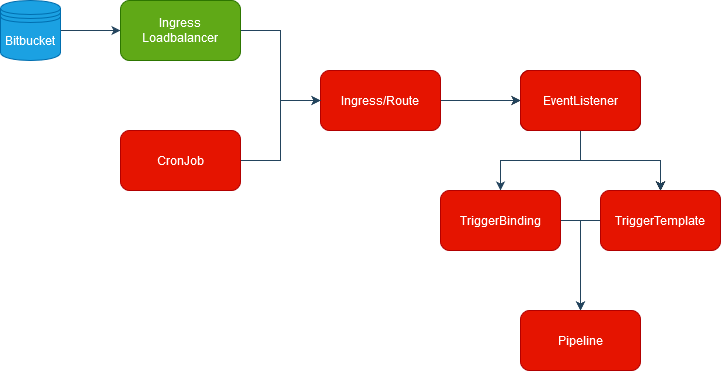
Run the pipeline in response to an event
Let’s start from the bottom: we have the pipeline, and in particular we’re interested in the pipeline parameters:
...
params:
- name: version
type: string
default: "4.31"
description: "Version to build"
- name: sourceGitBranch
type: string
default: 'develop'
description: "Branch"
- name: prDestinationBranch
type: string
default: ""
description: "PR Target branch"
- name: prRepositoryName
type: string
default: ""
description: "PR repository branch"
- name: GitOpsBranch
type: string
default: "prod"
...To trigger a pipeline run we have to create a pipeline template, which basically states which pipeline run (via pipelineRef), with which workspace (in this case we are specifying a pvc which supports read-write-many) and with which parameters.
Note that some parameters (such as version) are hard-coded, while other are taken as params, like we saw in the previous blog-post. Here the difference is that you have to use tt.params.<param_name> where tt stand for TriggerTemplate. As usual you can specify additional properties like timeout, etc…
apiVersion: triggers.tekton.dev/v1beta1
kind: TriggerTemplate
metadata:
name: my-pipeline-pipeline-template
namespace: openshift-pipelines
spec:
params:
- name: sourceGitBranch
- name: prDestinationBranch
- name: prRepositoryName
resourcetemplates:
- apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: my-pipeline-
spec:
pipelineRef:
name: my-pipeline
timeout: 1h0m0s
workspaces:
- name: shared-workspace
persistentVolumeClaim:
claimName: ug-pipelines-pvc-rwx
serviceAccountName: openshift-pipelines
params:
- name: version
value: "4.31"
- name: sourceGitBranch
value: $(tt.params.sourceGitBranch)
- name: prDestinationBranch
value: $(tt.params.prDestinationBranch)
- name: prRepositoryName
value: $(tt.params.prRepositoryName)
- name: GitOpsBranch
value: "prod"But where do the trigger templates take their values from? Of course you’ll need an additional object to map something to the trigger template, and this object is called a TriggerBinding:
---
apiVersion: triggers.tekton.dev/v1beta1
kind: TriggerBinding
metadata:
name: my-pipeline-bitbucket-binding
namespace: openshift-pipelines
spec:
params:
- name: sourceGitBranch
value: $(extensions.pr_source_branch_name)
- name: prDestinationBranch
value: $(extensions.pr_destination_branch_name)
- name: prRepositoryName
value: $(extensions.pr_source_repository_name)As you can see, here you are mapping some fields contained in the extensions object to the TriggerTemplate arguments. And this extension object comes from the EventListener:
apiVersion: triggers.tekton.dev/v1beta1
kind: EventListener
metadata:
name: my-pipeline-bitbucket-listener
namespace: openshift-pipelines
spec:
serviceAccountName: openshift-pipelines
triggers:
- name: my-pipeline-bitbucket-trigger
interceptors:
- ref:
name: "bitbucket"
params:
- name: eventTypes
value:
- pullrequest:created
- pullrequest:updated
- ref:
name: "cel"
params:
- name: "overlays"
value:
- key: pr_source_branch_name
expression: "body.pullrequest.source.branch.name"
- key: pr_destination_branch_name
expression: "body.pullrequest.destination.branch.name"
- key: pr_source_repository_name
expression: "body.repository.name"
bindings:
- ref: my-pipeline-bitbucket-binding
template:
ref: my-pipeline-pipeline-templateStarting from the bottom, you can see that the EventListener maps a (trigger)binding to a (trigger)template.
The other relevant part of the EL is the triggers section: in this case it contains two interceptors:
- The bitbucket interceptor is specific to Bitbucket and in this case we will be filtering requests by accepting only PR (pull request) creation and updates. Equivalent interceptors are also available for other repositories like Github.
- The cel interceptor is useful for parsing raw requests (the Bitbucket interceptor is quite limited). In this case we will be extracting several JSON fields and storing the results in an extension.<key> value, which is used by the TriggerBinding above. Here you can find the documentation about Bitbucket events, which are quite large objects and so we won’t show them here.
At this point almost everything is in place, but you still cannot start a pipeline in response to an external event. To do this you have to use an Ingress (or a Route) to make the EventListener reachable. Basically, Ingresses are standard Kubernetes, while Routes are OpenShift-specific objects with additional features, but are still fully compatible with Ingresses. Here you can find a more detailed explanation.
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-pipeline-bitbucket-listener
namespace: openshift-pipelines
spec:
rules:
- host: example.com
http:
paths:
- backend:
service:
name: el-my-pipeline-bitbucket-listener
port:
number: 80
path: /my-trigger/
pathType: PrefixYou must pay attention to the service: the Ingress (or route) must point to the service named like the EventListener with el- prepended. For example, to invoke my-pipeline-bitbucket-listener you must use the service el-my-pipeline-bitbucket-listener .
Run the Pipeline Periodically
At this point, provided that Ingress is properly exposed, you should be able to trigger the pipeline in response to an event, for example the opening of a PR on Bitbucket. In case you need to start a pipeline periodically and not (or not only) in response to an event, you’ll have to add a CronJob:
apiVersion: batch/v1
kind: CronJob
metadata:
name: azure-provisioner-build-job-core
namespace: openshift-pipelines
spec:
schedule: "0 5 * * *"
concurrencyPolicy: Forbid
failedJobsHistoryLimit: 3
successfulJobsHistoryLimit: 3
jobTemplate:
spec:
template:
spec:
containers:
- name: azure-provisioner-pipeline-trigger
image: curlimages/curl:latest
env:
- name: branch_name
value: "my_branch"
args:
- /bin/sh
- -ec
- "curl -d '{..}' -H 'Content-Type: application/json' -X POST 'http://example.com/my-trigger/'"
restartPolicy: Never
To trigger the pipeline you need to create an object to call Ingress via curl, you can even parametrize some variables defining them in env and using them as normal environment variables inside the container.
In the metadata section you can see that you can just insert a cronjob time to launch the command periodically; you can also see other parameters concerning concurrency and history cleaning.
Conclusion
As you can see, triggering is quite complex and requires a lot more objects than the pipeline itself does, and we struggled quite a bit the first time we implemented a trigger for our pipelines. Furthermore there are some pitfalls (like the el- prefix and tt. object) which are not straightforward.
My hope is that this blog post makes it a bit clearer how triggers work and gives an overview of the entire structure.
These Solutions are Engineered by Humans
Did you find this article interesting? Are you an “under the hood” kind of person? We’re really big on automation and we’re always looking for people in a similar vein to fill roles like this one as well as other roles here at Würth Phoenix.







Alessandro Valentini
DevOps Engineer at Wuerth Phoenix
DevOps Engineer at Würth Phoenix
Author
Latest posts by Alessandro Valentini
04. 03. 2025
Automation, DevOps, Service Management
Group-aware Reboot with Ansible
31. 12. 2024
DevOps
GitOps: Pull-based vs Push-based Approaches
16. 12. 2024
Development, DevOps
NetEye and RHUI Repositories