
In this article we’ll discuss the security concerns caused by Google’s introduction of .zip domains.
First things first, let’s understand what a domain is and how it’s structured.
What is a domain?
A domain is a text string that allows a user to access the specified web site once typed into a browser. This string is converted into an IP address, which is used to identify the correct server hosting the website on the internet, thanks to a service called DNS. But we won’t dig too much into this aspect here.
A domain is composed of different parts, each separated by a dot. The last part is called the “top-level domain”, abbreviated as TLD.
For example, in the URL www.neteye-blog.com, the TLD is ‘.com‘.
Top-level domains can be very diverse, from country-code top-level domains (ccTLDs) reserved for countries, such as .it, .uk, .fr or .de, to generic top-level domains (gTLDs) that are more generic, such as .xyz, .health, .market, .name, and many others. The complete list is available here.
Domains are managed by a number of entities called domain registries. A domain registry is an organization that maintains administrative data for one or more top-level or lower-level domains. These registries cooperate with different domain registrars, delegating to them the reservation of domain names. Every internet user has the possibility of registering one or more domains of their choice with a registrar.
There are a lot of TLDs, but some of them seems more relevant than others.
Why do .zip domains worry researchers?
In early May, Google Registry launched eight new TLDs. Google Registry works with several domain registrars (such as Google Domains, GoDaddy, Namecheap and many others) who allow users to register a domain. It’s normal for Google Registry to release new TLDs, but unlike previous times, security researchers have raised concerns about the potential dangers of two TLDs in particular: .zip and .mov.
It’s possible (and in fact it’s already happened) to register domains such as archive.zip, backup.zip, report2023.zip or microsoft-office.zip, which can be used by attackers for malicious purposes. In fact, these names resemble compressed folders and can be used in phishing emails as bait to trick the end user. On the other hand, .mov extension resembles a video file, so domains such as example.mov, video.mov, instructions.mov or others can be used to host malicious files pretending they are videos.
Advanced attacks
The problem doesn’t end here, as malicious actors can carry out even more sophisticated attacks. The use of these TLDs in combination with the @ and the unicode characters U+2044 (⁄) and U+2215 (∕), allows threat actors to create extremely convincing phishing campaigns. To understand how this works, we must first understand the elements that make up a URL.

As shown in the image above, a URL can consist of several parts. It doesn’t necessarily have to contain all of them, but it will always have at least the scheme and the hostname.
Everything between https:// and the @ character is considered user information, used by the source to access the website. However, modern browsers ignore this data and consider only the host name part for website resolution. This means we can insert arbitrary text before the @, because the browser will ignore it anyway.
Here is an example you can try for yourself:
https://example@google.com–> redirects to google.comhttps://this_is_incredible@www.neteye-blog.com–> redirects to www.neteye-blog.com
It’s possible to create fake URLs that are almost indistinguishable from legitimate ones by using special unicode characters identical to the legitimate slash (/) inserted before the @.
In the following example, kindly provided by user @bobbyrsec on Medium, we can see the differences:
https://github.com/kubernetes/kubernetes/archive/refs/tags/v1.27.1.zip–> Legitimate URL, makes you download a genuine compressed archive.https://github.com∕kubernetes∕kubernetes∕archive∕refs∕tags∕@v1271.zip–> Malicious URL, redirects to https://v1271[.]zip, which makes you download a malware.
This happens because the two characters U+2044 (⁄) and U+2215 (∕) placed before the @ are treated by the browser as “text to ignore”. But since they clearly resemble a real slash, they deceive users into thinking they are clicking on a genuine link.
What can we do?
To protect ourselves there are several recommendations we can follow. Luckily there are some easy tricks to understand if the URL we are clicking on contains the characters U+2044 (⁄) or U+2215 (∕). If we copy and paste the URL in a new tab, the browser will show us the actual domain it will redirect us to:

Unfortunately this preview only works in Chromium based browsers and not others like Firefox.
Another tool we can use to check the output of the URL is Cyberchef. This multi purpose web app contains a feature called Parse URI that breaks down a URL into its basic components.
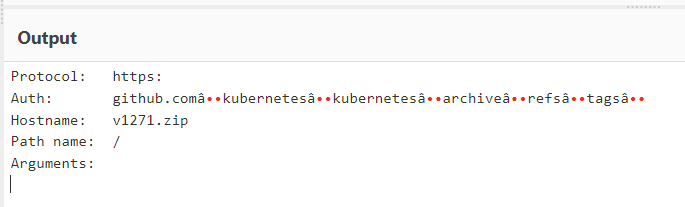
To see the same example or try different URLs navigate here.
Last but not least, check the URL for the @ character, as it’s necessary for this malicious redirection trick to work. It’s important to remember, however, that for links received by email, the @ character may be hidden, so it’s always better to check the link with one of the two methods described above.
These Solutions are Engineered by Humans
Did you learn from this article? Perhaps you’re already familiar with some of the techniques above? If you find security issues interesting, maybe you could start in a cybersecurity or similar position here at Würth Phoenix.







Mirko Ioris
Technical Consultant - Cyber Security Team | Würth Phoenix