
A Developer’s Life is Like a Box of Chocolates: You Never Know What Bug You’re Gonna Get – Part 2
Intro
This post continues the analysis of a bug I had to deal with recently. If you missed the first part, I suggest you go take a look at it before continuing with this. If, on the other hand, you’ve been anxiously waiting for this post XD, we’re ready to get into the thick of things!
Small recap: we have a web page that’s super slow, the content remains empty, and the browser keeps showing the loading icon on the tab title. After an initial analysis we have ruled out that the problem may be server-side, or in the transfer of resources from the server to the client. So, after steps 1 and 2, it’s time to focus on what’s happening on the client side: JavaScript and style sheets.
Process
Step 3 NOT optimized: Analyze JavaScript scripts
At this point, I assumed that there was some JavaScript script that was somehow blocking the page, resulting in a frozen browser window. For example, some recursive operation on the DOM elements might have been using the setTimeout or setInterval function. Not knowing the application in depth, I decided to once again adopt a research strategy by exclusion.
I started by excluding one script at a time, trying to see whether the problem recurred or not. By exclude, I really mean to comment out the inclusion of that JavaScript file to prevent it from being loaded into the DOM. In case it didn’t recur, I’d then focus my attention on the very last script I had excluded. Of course, it didn’t work out that way. I got as far as excluding all the files containing JavaScript but the problem kept showing up in the browser.
Considering that the scripts had been divided into lots of files and that there is a system that combines them into one file and compresses them before including them in the DOM, I began to wonder whether I was really excluding them or not. I started asking myself questions and getting confused. This made me waste time. A lot of it. I couldn’t believe that the problem was neither server-side, nor on the connection, nor on the JavaScript scripts. Eventually I had to give up.
Result: It was time to move on to analyzing what I hoped I wouldn’t have had to, and get out of my comfort zone. In the entire technology stack, it’s what I was least familiar with: style sheets.
Step 3 optimized: Analyze page performance using the browser’s built-in analysis tools
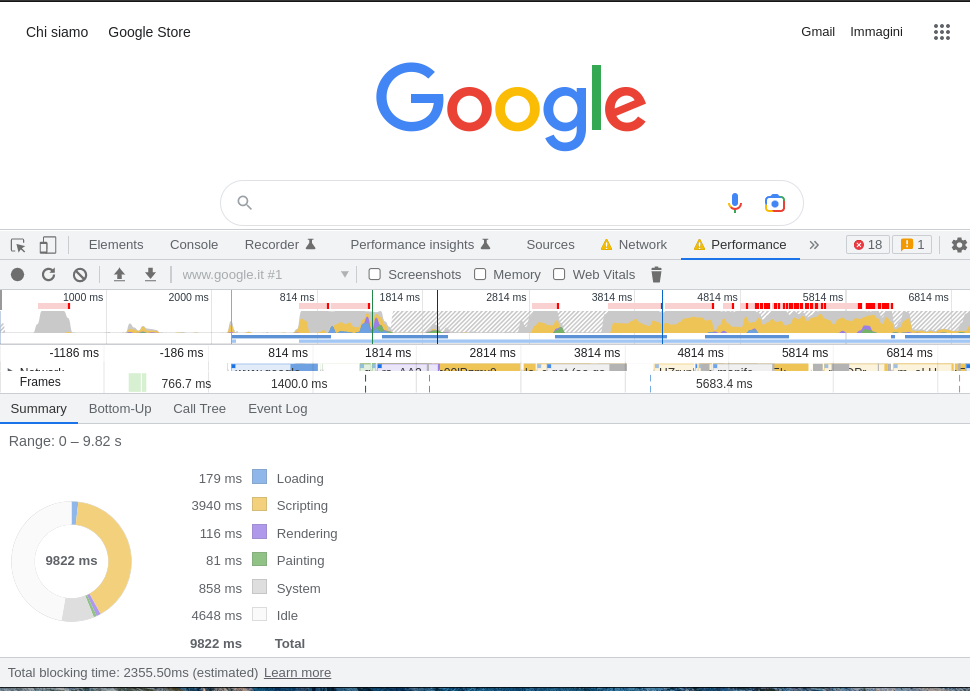
Well yes, I had fallen for it again. There was a much faster way to get to the same result. As with analyzing requests from the client to the server, the browser’s built-in developer tools provide a specific feature to analyze web page performance. Specifically, I used Google Chrome’s “Performance” tool – most of the widely used browsers also have similar tools.
Among the graphs resulting from the analysis is a pie chart that summarizes the total page load time, by dividing it into the following categories: “Loading,” “Scripting,” “Rendering,” “Painting,” “System,” and “Idle.” What emerged from that graph was fascinating, all categories had normal execution times. The only exception was the “Rendering” category which took about 120 seconds to execute. An enormity.
The “Rendering” category corresponds to the task where the browser applies style sheets to DOM elements. At this point, it was clear that the JavaScript scripts were not the culprit for the slowdown and that the style applied to the page was in fact the culprit. All very funny…
Result: a couple of minutes to achieve the same result as the unoptimized step 3, which took me a good hour.
Step 4: Find out the problematic style sheet
The project includes a lot of style sheets that, like the JS scripts, are compressed and minimized into a single file before being sent to the browser. As with JavaScript, the only way I could quickly get to the section of code generating the problem was to start excluding one file at a time…
The process in reality wasn’t exactly straightforward initially, for someone like me who had never seen SASS before. I eventually got the hang of it, though. In a half hour or so I was able to isolate a file that if excluded made the rendering of the web page go back to within normal timing.
I had finally reduced the search range to a single file! I was so close to the end of my suffering XD, I just had to figure out which, among the more or less 600 rows contained in that file, was responsible. At this point I reversed the search method: from a search by exclusion to a search by inclusion.
So I commented out the entire content of the file and began uncommenting a single chunk at a time, starting at the beginning. Each time the page would load normally, I would uncomment the next piece of code.
Obviously the problem was in the last 20 lines of code LOL:
&[disabled] ~ * {
opacity: .25;
}I didn’t have a clue what those 3 lines of code did or how to fix them, but inside I was exploding with joy at my victory. I had found the cause of the bug!
Conclusions
You can get to the cause of a problem even without knowing the technology at all but applying a certain search logic. And this search logic can be applied to any technology. Very often what blocks us from getting to the cause of a problem is just not applying a technique correctly or choosing the wrong method.
Unfortunately, even after some research and after talking with some colleagues more experienced than me in the area of web page rendering with style sheets, I couldn’t find a faster methodology that would achieve the same results as step 4.
Feel free to leave me a comment if you have any advice that would be helpful in improving the research process I applied, but also to share your own experience or just to let me know whether or not you liked this post.
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.






