





01. 10. 2025
Atlassian, Service Management

15. 12. 2022
Fabrizio Dovesi
Service Management
Data-driven Models – the Ultimate Fighter Against a Company’s Complexity 👊 – Part 1 of 2
Guidelines for data-driven models for managing data complexity and designing robust systems that might be considered both a single-source-of-truth and a single-point-of-contact.
In the last few decades the world has truly turned into a data jungle: digital evolutions expose people and companies to dealing with data complexity management, a topic which has rapidly turned into a leitmotif nowadays.
That said, the success of data-driven approaches to business has increased the need for both Integrations and Automation but, at the same time, as organizations become more and more data-driven, they typically begin to implement many disparate technologies sourced from different providers.

This is the “silent” way that a company embraces exponential and, frequently, unmanaged complexity on its data model!
If something goes wrong with this, the typical effects are: data spread into multiple tools, commonly duplicated and possibly not updated, or user frustration due to working with inconsistent data/documentation and with many different separate systems (by wasting so much time on low-value redundant activities), or “mysterious” procedures currently in place, and so on.
Both medium-sized and large companies are potentially affected.
For medium-size organizations, this tendency can make it difficult to scale up.
For larger enterprises, the trend is to become more chaotic, and thus more and more expensive to manage.
There is only one mix of ingredients that can turn it into a manageable system:
- Integrations
- Automation
- Consistent and updated data
- Processes and procedures
- Monitoring
- “Thinking” people

Once skilled, expert people properly mix them up, you will have in place a system that may represent both a Single-point-of-Contact and a Single-source-of-Truth for all the users involved. This will be the final goal that keeps the entire system manageable while also making users happy.
Moreover, well managed data not only helps keep internal complexity under control, but it even enables customer interactions: think about tasks such as granting customer permissions only on specific, pre-authorized and recognized perimeters/services, or retrieving SLA data, or sharing requests with other customers in the same organization, etc.; they are all based on data. So that’s why their quality, availability, and consistency are so important in creating a sustainable model and must never be endangered!
Communication processes and flows must be driven by the data interaction across all involved people:
If the model is driven by the customer’s perspective first, the focus on customer expectations and rights is ensured. In one sentence, the must-have is: Individuate the data needed by customers.
Some examples are data on services/product information, customer/organization data, financial and contractual data (such as contract’s validity), assets, etc. .
But customer perspective is not the only thing that has to be taken into account when designing a data driven model: another secret to boosting service management processes is to enable operators to quickly gather customer’s information during their activities.
- Customers’ recognition
- Customers’ data
- Contract validity
- Delivery state
- Account receivable collection state
- Authorization process
- Customization list

Finally, we have to consider other collaborators which act around the service management such as Sales representatives, Suppliers, Partners, Administrative, Back office, etc. Each of them has a key role in guaranteeing the expected quality of overall service. Therefore, they must be granted dedicated permissions: to view a restricted set of data they need to see and do what they need to complete a task (if needed). On the other side, data on vendors, partners, and even on internal colleagues are always desirable to have available in case needed by operators. When this is mixed up with a strong and well designed communication across all actors, it’s something that will bring great benefits to everyone.
As I wrote earlier, there are several required ingredients to create a well designed system.
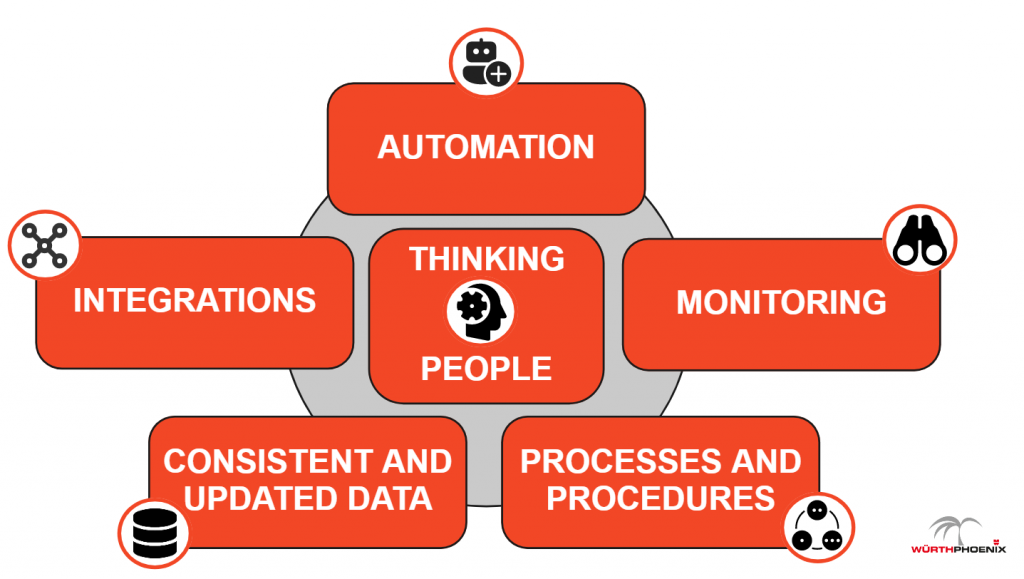
Below I’ll briefly explain each one.
Integrations
System integration (SI) is a process that connects multiple IT systems and applications in a company so that they work consistently in a coordinated and unified manner. Without integrations that are well planned and implemented, the likelihood that many disparate technologies will lead to data and information silos can only grow ever larger, causing loss of credibility and therefore the reliability of the data.
Automation
The acceleration of the delivery of IT infrastructure and applications to achieve outcomes with minimal human input: Automation is the process of building software and systems in order to replace repeatable processes and reduce manual intervention. As already discussed in my previous post (Link), well designed and managed automation bring great benefits to all the people part of the process: from customers to the operators’ perspectives, automation lets you avoid repetitive, boring and frustrating activities in order to get users focused on what they really need to do, and then support them on it (e.g., by providing just-in-time and just-in-case data to the operators when a given event occurs on the customer side).
Consistent and updated data
It should be pretty easy to figure out that there is only one thing that must be available to make a Single-source-of-Truth model become reality: your data must reflect the truth. It’s simple for everyone to understand how much fresh, updated and consistent data represents one pillar of the data driven model. If data are misaligned, duplicated, outdated or not consistent, then the service quality level will rapidly fall, people will get frustrated and confused,duplicated work and efforts will increase, and so on.
Processes and procedures
A process can be defined as a series of actions or steps taken in order to achieve a goal, a particular end or to provide an efficient service. They are related to procedures, which are an established, shared or official way of doing something. Therefore, we talk about the importance of defining who does/views what, which is the required data at predefined steps of the process or to complete a task, and so on.
Monitoring
Another pillar of the data-driven model consists of monitoring the health and resource utilization of IT components; in other words, to ensure an IT environment’s hardware and software functions as expected. In many cases, teams who are in charge of managing IT systems are actually more likely monitoring their company’s core functionalities, rather than just “hardware, software and applications”, without a real consciousness of this. Therefore, monitoring has to be consider a “must” since it represents a structured way for spreading this culture, and is even the most powerful “elevator” of credibility when IT teams rapidly react to unpredictable events.
“Thinking” People
Last but not least, even if we are working in the best integrated, automated, etc. environment, ….yes: we still need people who can think for themselves. All the people involved in a given process are crucial in some way to properly providing the service. Feedback, interactions, ideas for improvements and so on, bring the desired effects only if we have thinking people who are able to transform them into positive actions and to properly interact with each other.
We are almost at the end of this post. I guess it’s still quite difficult to get an overall idea of what we mean by a “data-driven model” without looking closely at a real Use Case.
That’s why, in the next episode, which is going to be published very soon, I’ll describe how all these topics come together into a real use case scenario, and where they are helpful to the users.
See you in the next episode!
These Solutions are Engineered by Humans
Are you passionate about performance metrics or other modern IT challenges? Do you have the experience to drive solutions like the one above? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles like this as well as other roles here at Würth Phoenix.
Author
Latest posts by Fabrizio Dovesi
01. 10. 2025
Atlassian, Service Management
Project Managers Are rAIsing the Bar: Redefining the Rules of the AI Game
30. 06. 2025
Atlassian, Service Management
Where ITIL® 4 Meets Atlassian: Elevating IT Service Management
21. 03. 2025
Atlassian, Service Management
Be a “Whiteboard Blackbelt” to Unleash Effective Collaboration
29. 12. 2024
Atlassian, Service Management
Let’s Repopulate the Community of “Pandas 🐼” Who are Happy with How Their Company Handles Documentation
29. 11. 2024
Atlassian, Service Management
The Importance of Being…Informed for Finding Your Way across All Jira Products!