





31. 03. 2025
NetEye, Service Management

If you’ve ever had cardinality problems with InfluxDB, you might have discovered that a tag is the likely culprit. Well done! But now your next step is getting rid of that tag, and that’s when you’ll realize that in a time series database, tags play an important role in indexing. Because dropping tags is rather complicated, let’s start with a very easy example and work our way up.
A Basic Example
Imagine three different values registered at the same time but differing in performance. These values are going to be written as a field into a measurement M, while the performance is written as a tag. The tags are part of the index (while fields are not) and therefore the combination of a measurement with the tags leads to 3 different time series, each containing a single value (at the timestamp when the data was registered).

Overwriting in the Case of the Same Timestamp and Same Tag(s)
Now let’s slightly change the scenario described above. Suppose instead of three distinct performance tags we only have two. This leads to two different time series, each having just a single value. In case you’re wondering where the second value has gone, it was written out before the third value. The second and third values have the same timestamp and the same tag. Thus as soon as the third value is written to the database, the second value gets overwritten.
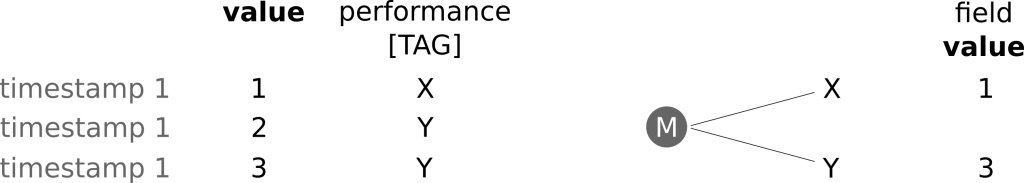
Different Time Stamps
If instead the timestamp of the third value was different than the timestamp of the second, both values would have been written into the database without the third overwriting the second.

Having understood the basic principles underlying indexing in InfluxDB, let’s make things a little more complex. Imagine a system containing 5 servers (Servers I-V). Here we register two different measurements (e.g. Processor and Transactions), where each measurement contains one or more fields. In our case the Processor measurement contains 2 fields, % Processor Time and % Privileged Time, and the measurement Transactions contains the single field Transaction/sec. This would mean 2 measurements, 3 fields = 3 time series. By using the different servers as tags to distinguish between them, it would become a 3 x 5 time series. Now let’s add another tag: SQL Instance, since the number of transactions per second on the same server could be different for different SQL instances. Let’s suppose we have two of them: SQL-I1 and SQL-I2. This means that the number of time series doubles for all measurements for Transactions: (2 x 5) + (1 x 5 x 2) = 20 time series. So far so good, as long as there are just a few time series, we don’t need to worry. But what are we doing by adding more tags? We are increasing the series cardinality.
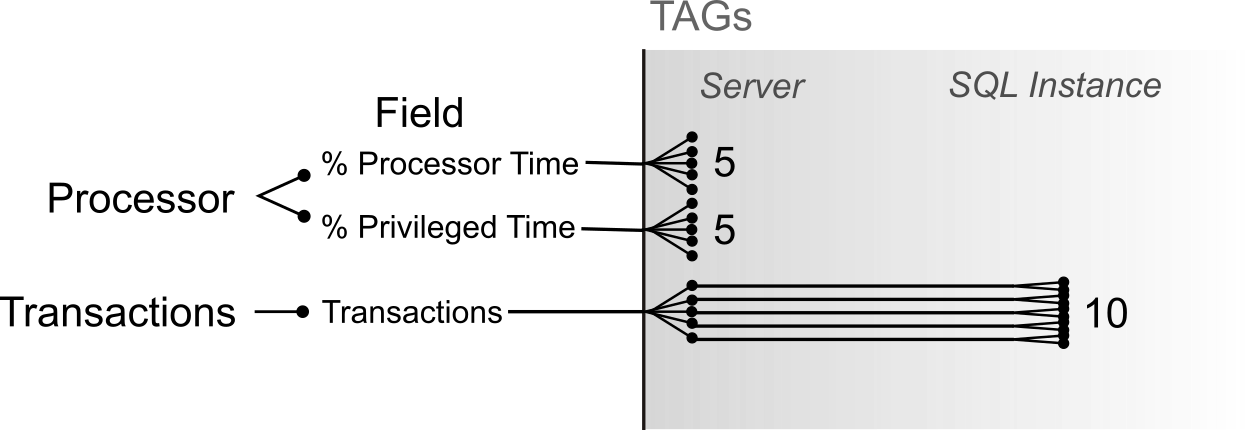
Series Cardinality
Why should you care about series cardinality? Because series cardinality is THE major component that affects how much RAM you need. According to the InfluxData hardware guidelines, the increase in RAM needed relative to series cardinality is exponential (with exponent below two) as follows:
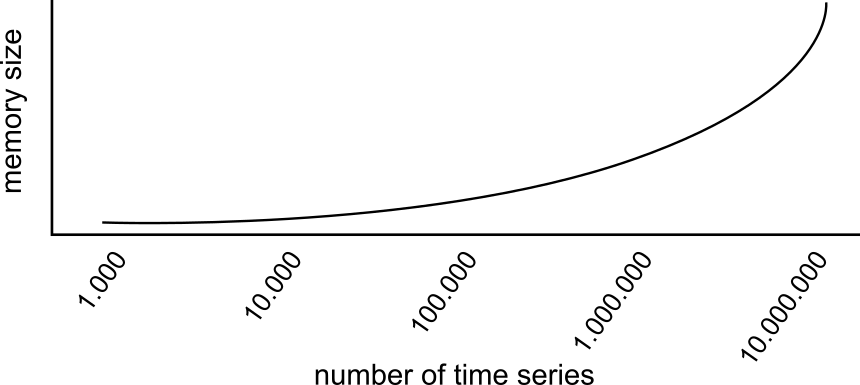
Advice for Choosing Tags
There are a few rules (schema layout) to respect when designing your schema:
- Avoid tags containing highly variable or unique information such as IDs, hashes, and random strings, as they will lead to a large number of time series (and thus high series cardinality)
- Always consider whether something should be a field or a tag. Time series that fall within the same field are merged by default, so it is better to differentiate them via tags than create more and more measurements (and partly encoding the tag information in the measurement name)
- One tag = one piece of information. Avoid tags with multiple pieces of information and split them into separate tags. Queries will become easier and most likely faster without needing regular expressions as often.
- Note: Tags can be used in a GROUP BY clause to group data that includes those tags. Tags written as a field do not allow for grouping. However, they can still be used in the WHERE condition of another field.
Let’s return to the example above and introduce two more tags. The first is an alert status tag that can take 3 values (e.g. ‘ok’, ‘warning’, or ‘critical’). The second is a string combined with a unique random number giving further information about the transactions running at the time of the time stamp, assigned just to the Transactions measurement. What would happen next is not difficult to explain: the status tag will increase the number of time series to (2 x 5 x 3) + (1 x 5 x 2 x 3) = 60 time series, i.e. a linear increase. But the second is the really dangerous one: each new time point will have a new tag, becoming a new time series, and the cardinality will explode. While Processor remains at 30 different time series, Transaction will grow in number with each new time stamp. If we write one entry every 20 seconds, then after a day there will already be up to 130,000 time series, and after a single week we will already be close to 1 million. Most likely you will have noticed before then that queries are taking longer (because a database with high cardinality also influences all read operations from that database). But if we have already introduced a tag that was not properly designed and now we want to get rid of it, what can we do?
Dropping a TAG
Dropping a measurement or series is easy:
DROP MEASUREMENT <measurement_name>
(drops all data and series in the measurement)
DROP SERIES FROM <measurement_name> WHERE <tag_key>='<tag_value>'
(drops a series with a specific TAG from a single measurement)
- The
DELETEquery deletes all points from a series in a database, but does not drop the series from the index. It supports time intervals in theWHEREclause (for more information, see the relevant InfluxData Documentation).
Dropping a TAG itself is not supported, because TAG values are part of the definition of a series (specifically, part of the index). They are never deleted from the index nor can they be, except by destroying the index itself. So if you want to drop a tag but keep its values, then some kind of workaround is needed.
You might think you can use the INTO clause to rewrite query results out to a new user-specified measurement. Is that possible? In principle yes, BUT you need to be very careful because of the special logic involved with the INTO clause.
As long as there are no data points with the same timestamp separated from the tag (the one we want to cancel), and as long as we only want to move one tag at a time, it is possible to simply copy (SELECT) the measurement into a new, temporary one. Then the measurement with the tag that needs to be removed can be canceled and the temporary one can be copied back as the actual measurement.
Note that:
SELECTfieldINTOmeasurement_tmpFROMmeasurement
needs to be used with GROUP BY in order to keep all the other tags one wants to keep. Otherwise as soon as there are more data points with the same timestamp, the one written first is simply overwritten by a later one, and the final result will be the last one written into InfluxDB. In the example above it’s easy to remove tags like the state tag or the string combined with the unique random number. Tags like SQL Instance or Server instead need a query like:
SELECTfieldINTOmeasurement_tmpFROMmeasurementGROUP BYTAG-1, TAG-2, …, TAG-n
Common Errors
It is possible to remove certain tags as described above without removing all of them (if you have more than one point with the same timestamp, you need to define what to do – e.g. aggregation – to achieve the right results). Always consider your schema in detail.
In case of a tag that splits multiple time series from each other, it is not possible to do without the tag: a removal will result in overwriting as explained above.

Given a tag like the status tag mentioned above, or in general, tags that split data into parts of a time series that would not overlap in the case of reunion, transferring a tag to a field is an option and can have a very pronounced effect on the cardinality.

The queries shown above need to be repeated for each series/field within the measurement. In this context
SELECT*INTOmeasurement_tmpFROMmeasurementGROUP BYTAG-1, TAG-2, …, TAG-n
is possible. BUT it also creates a new series containing the values of the removed TAG (which can be handy when transforming TAGs into measurements used for annotations).
Check your results BEFORE destroying your original measurement (e.g. by looking at the resulting graph).

Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential