
Unseren Glückwunsch an die Gewinner des NetCla Challenges!
Mehr als 100 Teams haben teilgenommen, mehr als 25 haben eine Lösung eingesandt, die besten haben einen Macro-F1 Score höher als 0.88 erreicht.
Letzten Freitag war es nach 6 langen Wochen endlich soweit. Auf der ECML-PKDD Konferenz in Riva del Garda wurden die erfolgreichsten Lösungsansätze beschrieben und diskutiert. Die Teilnehmer hatten die Möglichkeit sich Fragen direkt vom Organisationskomitee beantworten zu lassen und Iryna Haponchyk – Leiterin des erstplatzierten Teams – durfte ihr Challenge Preisgeld von 1000 Euro in Empfang nehmen als Anerkennung für die Lösung mit dem höchsten Macro-F1 Score, bzw. vielmehr für das Modell, das in der Lage war einen so hohen Score zu erzielen. Im Bild ist die strahlende Gewinnerin bei der Preisübergabe zu sehen.

Iryna erklärt, ihr Team hat einen linearen standard multi-class SVM Klassifikator trainiert. Vorher haben sie allerdings das bestehende Feature Set mit weiteren Features angereichert. Diese wiederum wurden zuvor einerseits durch Random Forest Methoden erzeugt, andererseits wurde die zeitliche Abhängigkeit verschiedener Instanzen berücksichtigt.
Lei Xu, der Leiter des zweitplatzierten Teams, dahingegen hat eine Lösung eingereicht, die auf einem Ensemble Approach basiert. Ein zentrales Modell, das mehrere Abfolgen von binärer und multi-class Klassifizierungen ausführt, um insbesondere das Ungleichgewicht der verfügbaren Labels je Klasse auszugleichen. Weitere Add-ons haben die Genauigkeit der Methode weiter verbessert.
Martin Wistuba, Leiter des drittplatzierten Teams, hat wiederum eine andere Lösung vorgestellt. Der Ansatz dieses Teams basiert insbesondere auf aktuellen Methoden für automatisches maschinelles Lernen. Ohne menschliches Zutun beim Preprocessing, Feature Engineering bzw. bei der Modell Parameter Optimierung wurde der dritthöchste Macro-F1 Score erreicht.
So weit, so gut, was lässt sich mit einem solchen Ergebnis konkret anfangen, bzw. hat das Ergebnis des Challenges auch Anwendungsmöglichkeiten in der Zukunft?
Fassen wir noch einmal kurz zusammen, worum es beim NetClaChallenge genau ging.
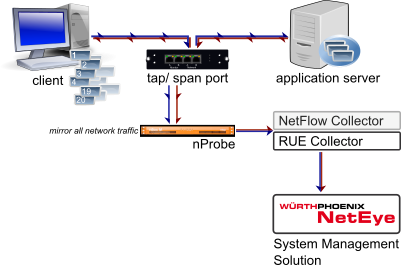
Würth Phoenix S.r.l. sammelt kontinuierlich große Datenmengen bis zur Requestgenauigkeit. Diese Daten können für die unterschiedlichsten Dinge verwendet werden:
- Trendanalysen um Engpässe ausfindig zu machen,
- Steigerung der Applikationsperformance und dadurch Verbesserung der Mitarbeiter-Produktivität,
- proaktive Vermeidung von kostspieligen Systemausfällen
um einige zu nennen.
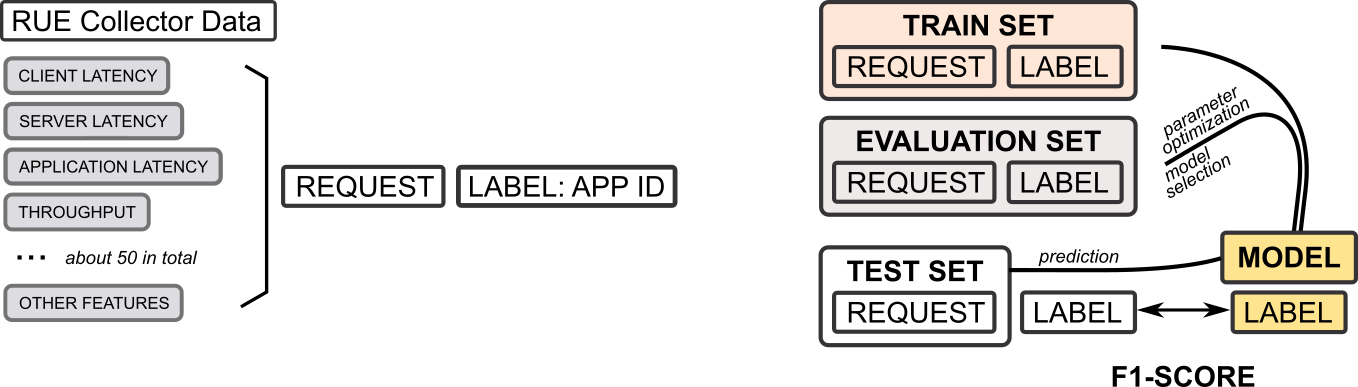
Beim NetCla Challenge ging es darum, anhand eines Trainings-Datensatzes ein Modell zu schaffen, welches dann auf einem ähnlichen Test-Datensatz Vorhersagen machen kann.
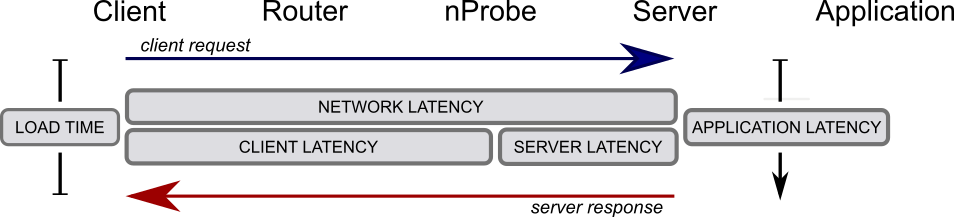
Im Detail zeichnet sich jeder einzelne Request durch verschiedene Metriken wie Latenzzeiten bzw. Throughput und viele mehr aus. Beim NetCla Challenge sollte anhand der Werte dieser Metriken vorhergesagt werden, welche Applikation den jeweiligen Request gesendet hatte (ein multi-class Kassifizierungstask).
Jetzt, wo wir wissen, dass es möglich ist mit hoher Genauigkeit die jeweilige Applikation vorherzusagen stellt sich die Frage, wie sich dieses Wissen verwenden lässt. Zum Beispiel kann ein solches Modell verwendet werden um Veränderungen im Netzwerk zeitnah zu bemerken (Sobald es schwieriger wird die Applikationen richtig vorherzusagen, könnten Änderungen positiver oder negativer Natur aufgetreten sein). Methoden, die auf maschinellem Lernen basieren haben hier im Vergleich zu Standard Methoden den Vorteil, dass sie Zusammenhänge zwischen den Metriken beachten und nicht nur einzelne Werte.
Der Datensatz des Challenges stammte von einem einzigen durchschnittlichen Arbeitstag. Um feststellen zu können, wie tagesspezifisch die Vorhersagen sind, sollte als nächster Schritt jeder der Algorithmen mit einem zu einem anderen Zeitpunkt aufgenommenen Datensatz getestet werden.
Hiermit gratuliert Würth Phoenix S.r.l. den Gewinnern, bedankt sich bei den Teilnehmern für ihren Enthusiasmus und wünscht den Teams auch weiterhin viel Produktivität in der Zukunft.






