
Congratulazioni ai vincitori della NetCla Challenge
Al concorso hanno partecipato 100 team, di cui 25 si sono dimostrati all’altezza della situazione e la migliore squadra ha raggiunto il punteggio Macro-F1 di 0.88
Venerdì scorso, dopo 6 lunghe settimane, è stato finalmente proclamato il vincitore del concorso durante la conferenza ECML-PKDD a Riva del Garda: dopo un’attenta analisi e discussione dei migliori approcci proposti dai Team, i partecipanti hanno avuto la possibilità di avere risposte alle loro domande direttamente dagli organizzatori ed è stato proclamato vincitore il team capitanato da Iryna Haponchyk. Ai vincitori un premio di 1000 Euro per aver creato la soluzione migliore che ha raggiunto il punteggio Macro-F1 più alto. Sotto, la foto con il team vincente durante la cerimonia di premiazione.

Iryna ha spiegato che la sua squadra ha addestrato un classificatore standard multi-class linear SVM, arricchendo il set di feature esistenti con feature generate da un random forest e funzioni che codificano le nozioni di interdipendenza tra esempi vicini nel tempo.Lei Xu, leader dei secondi classificati, ha proposto una soluzione basato su un unico modello, che esegue una sequenza di classificazioni binarie e multi-class per sistemare gli squilibri del target-class, e un po’ di tuning che aumenta ulteriormente l’accuratezza del modello.
Martin Wistuba, leader dei terzi classificati, ha presentato una soluzione totalmente diversa. il loro approccio è basato sul metodo di apprendimento automatico delle macchine, quindi non è richiesto alcun intervento umano nelle fasi antecedenti al processo, nella creazione delle funzioni e nemmeno nell’ottimizzazione dei parametri.
Ma qual’è il risultato concreto dei vincitori e come verrà utilizzato in futuro?
Fatemi riassumere brevemente lo scopo del concorso:
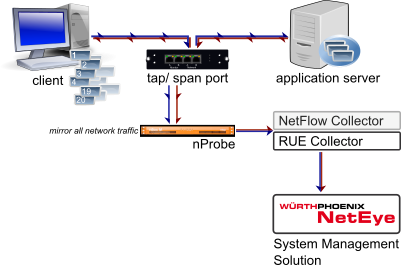
Würth Phoenix S.r.l. colleziona il traffico dei dati di rete per ogni singola richiesta. Questi dati possono essere utilizzati in vari modi, tra cui:
- analisi dei trend per rilevare le fonti dei colli di bottiglia,
- miglioramento delle performance e quindi aumento della produttività degli utenti,
- management awareness tramite report SLA,
- prevenzione proattiva di downtime di servizi IT
Lo scopo del concorso NetCla consisteva nella creazione di un modello in grado di predire parte dei dati di un giorno lavorativo medio una volta addestrato su un’altra parte di dati dello stesso giorno.
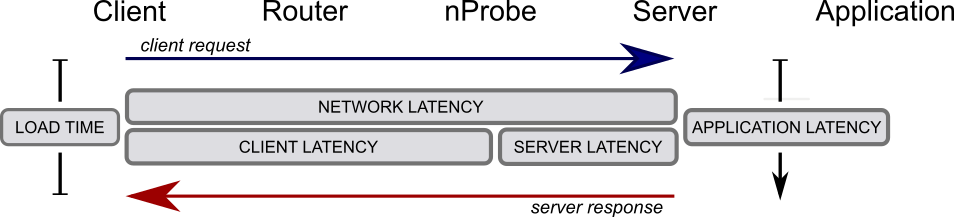
Ogni richiesta è caratterizzata da diverse metriche, ad esempio latenze e throughput misurate dalla sonda. L’obiettivo era quindi, data una trasmissione nella rete, di prevedere le applicazioni che trasmettono i dati (single label, multi-class classification task)
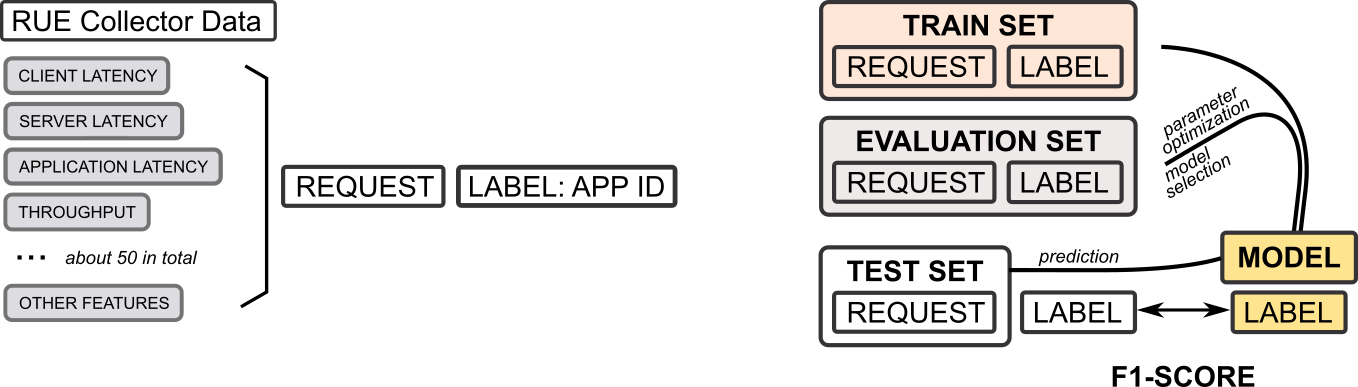
Adesso sappiamo che è possibile risalire alle applicazioni (o i servizi), analizzando le caratteristiche del traffico di rete. Questo dato a cosa può essere utile? Per esempio per controlli di potenziali cambiamenti della rete (quando il traffico di rete diventa difficile da prevedere, vuol dire che potrebbe esserci un problema da risolvere). I modelli basati sul Machine learning sono molto più sensibili a tali cambiamenti rispetto ai metodi comuni che sono basati su media giornaliera di certe metriche.
I dati utilizzati nel concorso si riferiscono ad un singolo giorno lavorativo. Dati analoghi ottenuti da diversi giorni possono essere usati per training e testing per ottenere una prima stima di quanto il modello e’ specifico per quel giorno.
Con la presente Würth-Phoenix S.r.l. si congratula con i vingitori del concorso NetCla, Li ringrazia per la loro partecipazione entusiasta e porge i migliori auguri per il futuro.






